

De-Glitching RAM Writes
Yesterday’s Nibbler celebration was premature – I discovered that about one in ten-thousand writes to RAM stores the wrong value. Bad RAM, bad! No biscuit for you!
Arghh, what a headache. I first discovered the problem while making improvements to the guess-the-number game. After many experiments, I was able to boil it down to a case where $F is written to RAM, but something else is read back. And I proved that it’s the write operation that’s going bad, not the following read. But that’s about as far as I’ve gotten in understanding why it fails, or how to fix it.
; Example 1 - fails consistently
#define TEST_LOCATION $038
testram:
lit #0
addi #15
st TEST_LOCATION
ld TEST_LOCATION
cmpi #15
jz testram
fail:
; turn on the debug LED
Example 1 adds 15 to 0, stores the result, reads it back, and checks to make sure it’s 15. If not, it turns on the debug LED to indicate a failure. This test fails consistently, after anywhere from zero to 10 seconds of operation.
; Example 2 - works reliably
#define TEST_LOCATION $038
testram:
lit #15
addi #0
st TEST_LOCATION
ld TEST_LOCATION
cmpi #15
jz testram
fail:
; turn on the debug LED
Example 2 is identical to example 1, but it adds 0 to 15 instead of 15 to 0. This test works reliably. How can that be? After all, in both examples the entire CPU is in the exact same state at the time of the store instruction. Wait, maybe it’s not the store that’s going wrong at all! Maybe the addi is faulty and computing the wrong sum?
; Example 3 - works reliably
#define TEST_LOCATION $038
testram:
lit #0
addi #15
cmpi #15
jz testram
fail:
; turn on the debug LED
Nope. Removing the store/load from example 1, which failed consistently, now works reliably. Head, meet wall. Bang, bang, bang.
Timing
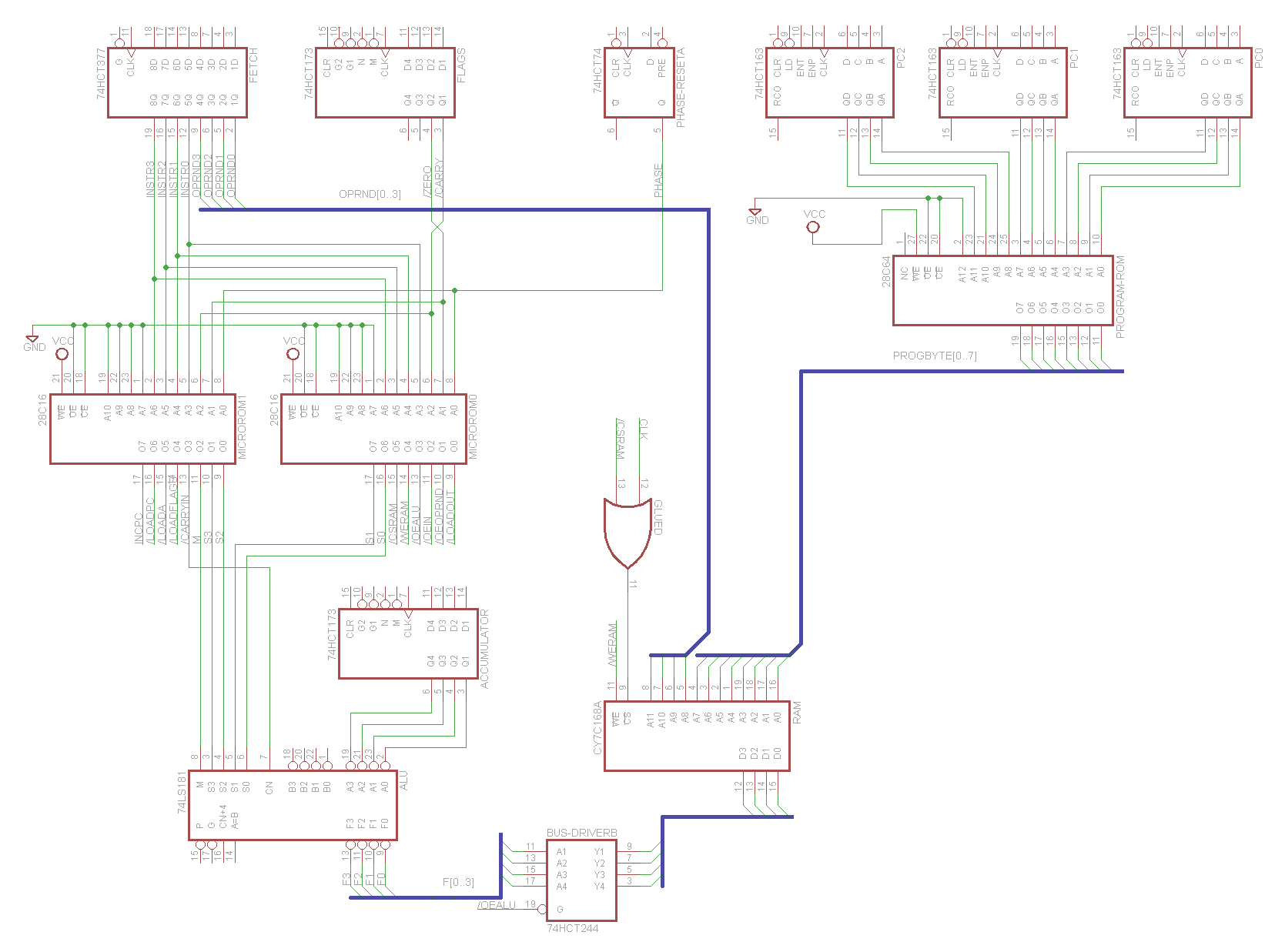
Click on the simplified schematic at the top of this post to see what’s involved while the accumulator value is being written to RAM.
My best guess is that at the end of a RAM write, either the data or the address are changing before the RAM /CS is de-asserted. /CS comes from a 74LS32 OR gate with a max propagation delay of 22 ns. The clock is one of the OR inputs, so /CS will be de-asserted no more than 22 ns after the rising edge of the clock. Could the RAM data or address be changing during this window?
Address: The high address bits come from the Fetch register, whose value never changes at the same time as a RAM write. The low address bits come from the program ROM, which has a 150 ns propagation delay, on top of the PC regsiter’s 39 ns tcq delay, so it seems very unlikely those values could change within 22 ns of a clock edge.
Data: The data is a little more complicated. The value coming from the accumulator won’t change, but the ALU function might, or bus driver B might become disabled, or something else might start driving the data bus and cause contention. All of those would require changing control signals in order to happen. Control signals come from the microcode ROMs, which have a 150 ns propagation delay, on top of tcq delays of about 30 ns for the registers at their inputs. So it seems unlikely the data values could be changing within 22 ns of a clock edge either.
A few other things I tried:
- Replaced the 74HCT244 bus driver with a 74LS244 – This helped a lot, but didn’t completely eliminate the problem.
- Changed TEST_LOCATION to $000 – The test still failed intermittently, but not as much as before
- Changed TEST_LOCATION to $FFF – The test passed reliably
I’m not even 100% certain that the problem is with address or data becoming invalid before the /CS de-assert. Maybe address isn’t valid before the /CS assert, or maybe there’s a glitch on /CS or /WE at some other time. But I don’t think so.
What I really need to do is hook up an oscilloscope or logic analyzer, and look at the relative timing of the clock, /CS, data, and address to see what’s going on. Unfortunately I only have one working scope probe, and even if I had more, I’m not sure the scope has enough resolution to see a timing error of a few nanoseconds. And even if I can demonstrate that data or address are changing before /CS de-assert, I’m not sure what I could do to fix it without major changes. Hmmmm…
Read 27 comments and join the conversation27 Comments so far
Leave a reply. For customer support issues, please use the Customer Support link instead of writing comments.
I should mention that the SRAM I’m using has a data hold time and address hold time that are both zero.
I think the problem may be that bus driver B is turning off before /CS de-asserts, so the RAM’s data is getting cut off. I tried rigging a 0.0015 uF capacitor between the driver’s enable input and ground, to make it slower to turn on and off, and that seems to have sort-of fixed the problem. More testing…
First ting to notice is that it always works reliable when the #imm value is the same as ADH (high address nibble) (I assume in your first test TEST_LOCATION was also something like 0xx out of programming convieniance) – which happen to go in both cases (OPC #imm and OPC abs) thru low nibble of FETCH and ADH-bus. Fetch shouldn’t realy add a problem here, since all RAM signals are generated by the micro code, which in turn is also feed by FETCH, so it’s contend should be rock solid. I would search arround the address generation part.
What I’m missing in your description is, how you did proof that it’s the read?
Hans, the test I did was to prove that the write went bad, not the read. In the “fail” section, after turning on the LED, I added some code to repeatedly load the RAM value and compare it against #15, and turn the LED off again if it ever matched. But it never did. It always read the same (wrong) value, so it must be that the wrong value was written.
That’s interesting that it works when the immediate value is the same as the highest bits of the RAM address. Might be a coincidence, or a good clue. I’ll look more into that tomorrow.
There as another read later on? Wasn’t clear from what you wrote. Hmm, maybe add here some immediate operation with #F before reading? Just to invalidate the ADH asumption I made.
Another area to check would be the micro programm: if /oeOprnd and /oeALU is asserted at the same time such a behaviour could happen – and delaying the ALUs result output might have worked against.
I do not realy belive in glitches, since this would require a fairly large one.
Also the asumption about Driver B truning off before CS gets deasserted seams strange – after all, /oeALU, /weRAM and /ceRAM are all driven by micro code outputs, so we should get exactly the same timing – even more /ceRAM is combined with CLK. CLK is driving any change in micro program, so deassertion of /CE should always be prior to /oeALU. Isn’t it?
Are you sure you are not leaving CMOS inputs floating somewhere? It is not good for them, and causes them to flicker, draw lots of current and destabilize the whole system. It should become evident when you hook up the scope.
Dawid – Yes, all unused inputs are connected to ground.
Hans – I ran another test which appears to rule out the #imm and ADH idea:
; Example 4 – works reliably
#define TEST_LOCATION $038
testram:
addi #0
lit #15
st TEST_LOCATION
ld TEST_LOCATION
cmpi #15
jz testram
Connecting unused inputs to ground does not fully solve the problem. I was rather thinking about a floating bus when a device has stopped driving it. In that case CMOS devices with inputs connected to the bus start misbehaving, too. You may need to try a bus-hold circuit to solve this (if this is really the case).
You might be on to something there. I was able to capture some data with the logic analyzer that shows it’s a data bus problem, and not a problem with the timing of the /CS de-assert.
Take a look at this timing trace for a bad write: http://www.bigmessowires.com/nibbler-la-error.jpg The X cursor is positioned at the end of the write cycle. This test was trying to write the number 5 to RAM. Take a look at D2 on the data bus – it’s a mess! No wonder the write failed. This doesn’t always happen, and when it does, it’s not always D2 that’s messed up. But whenever there’s a bad write, I see a pattern like this on at least one of the data bus lines.
My thought is this is either bus contention, or a problem with the bus not being driven at all. But so far I haven’t been able to find evidence of that.
I tried 10K pullups on all the data bus lines, so they would never be left to float, but it didn’t seem to help.
Then I discovered a huge problem: the Phase/Reset chip wasn’t even connected to power, and also the /WE inputs on the microcode ROMs weren’t connected. How did it even work? After I fixed those issues, I thought for SURE that would explain the problem with bad memory writes, but no. It still doesn’t work consistently. 🙁
OK, removed the 10K pullups, and added 22 pF capacitors between power and each data bus line. Now it works. I’m not sure what to conclude from that, or how it could explain the apparent bus contention or bus floating that I saw in the timing trace.
Glad it worked out. Did you do a test between removing the 10K and addign the capacitors?
I don’t really feel like the 22 pF capacitors are a permanent solution, but more of an interesting experiment.
After removing the 10K pullups but before adding the capacitors, it still didn’t work.
I just now did another test: removed the 22 pF capacitors again, and replaced the 74HCT244 bus driver with a 74LS244. That works too. It’s the same configuration that yesterday I said “helped a lot”, but that was before I discovered the unconnected pins on the Phase register and microcode ROMs. I like the LS244 better than adding discrete capacitors, but I still can’t explain what’s going on. There’s definitely something bad happening with the data bus, and the bus driver is part of it, but I can’t quite nail it down.
Edit: actually the LS244 still fails, after about five minutes running the test.
OK, I think I have a solution, albeit not an explanation! After undoing all the previous modifications, I made two new changes:
– I edited the microcode so that the data bus will never be left floating, to avoid the problem Dawid mentioned. Any time nothing is using the bus, the ALU will drive it anyway. That got the “testram” test working, but the original program that led to all this (an audio tone generator) still didn’t work.
– I replaced the Fetch register with a ‘LS377 instead of a ‘HCT377. This was after I noticed that the CPU worked better when I touched some of Fetch’s pins with my finger. Now everything works correctly, as far as I can tell.
At first I thought maybe the ‘HCT377 was simply loose in its socket, but that wasn’t it. The ‘LS377 definitely makes the difference, but how or why I can’t explain. There’s no timing dependency with Fetch, and no CMOS inputs that could be left floating to cause problems. Fetch isn’t even connected to the databus, so I don’t know how it could explain the apparent bus contention I saw. Maybe it wasn’t contention at all, but some kind of CMOS output oscillation.
The enable signal to the input port goes directly from the microcode ROM. Is there possibly a problem with glitches and that the input port is driving the bus? Remove it and test.
The same about the bus driver between the operand bus and the data bus. Maybe you have to qualify the enable by the clock signal.
Hi Lennart. Those were my first thoughts as well. I did try physically removing the input port driver chip, but it didn’t help. Unfortunately I can’t remove the operand bus driver without impacting the CPU operation. When I used the scope to look at the enable signals for the input port and the operand bus driver, they looked fine. And a glitch on either signal should cause momentary bus contention, not contention that lasts for the entire clock cycle like what’s shown in the photo of the timing trace.
Have you checked the signals at the ALU output?
Are all the signals from the micro-ROM stable? Other enable signals, ALU inputs, etc.
I noticed something else odd while checking the ALU and microcode ROM. The scope measures between 4.93v and 5.12v between the power and ground planes, but almost every time-varying signal I’ve looked at swings through a wider range. For example program ROM bit 0 swings from 5.6v to -0.25v, S2 (an ALU function input) swings 5.75v to -0.06v. I’m not sure if those voltages are real, or some kind of artifact of the scope probe or something. The signals themselves look pretty clean and square, with just a small amount of overshoot at each edge, but the plateaus are always above VCC or below ground. How is that possible? If I measure a control signal that’s not changing, like /OEIN, it measures a steady 5.06v.
On closer inspection, this seems to be an artifact of the new probes I just bought. The one remaining old probe I have shows 5.0v for these signals. I guess I shouldn’t have bought the cheapest possible scope probes.
Edit: Hey, there’s an adjustment screw on the probes! Working much better now.
Can’t help to wisecrack – whenever you stored your stuff for some time, recalibrating the probes with the test signal is a good idea 🙂 And just rechecking every time you start … after all, Digital is still way much analogue 🙂
Oh, and to be a bit more helpful: have you tried to lower the clock rate? Let the baby run at 100 kHz and see if you still get false results. If yes, it’s most certain a race condition between signaly when changing – if yes, you’re just outruning some components (EEPROMS are good candidates here).
OK, I was finally able to determine that the bad data bus voltages are coming from the ALU, and not caused by bus contention. Since the ALU is isolated from the bus by a driver, I was able to test on both sides of the driver to see where the badness was coming from.
So why does the ALU generate bad values? I checked the accumulator and the S, M, and carry-in inputs, and they all look good. And the ALU function is set to output=A, so the value on the data bus at the ALU’s B input shouldn’t matter.
Here’s what I think might be happening, but it’s a shaky theory. At the start of a clock cycle for a write to RAM, the ALU function select inputs will be changing. Say they briefly land on a function that involves the use of the B input (the data bus). But the ALU is driving the data bus now, so its own output also becomes an input, and you get a combinatorial feedback loop. Depending on the specific function, this could easily end up trying to drive a data bus line to the opposite of its current value, forcing it into a invalid logic state around 2.5v.
After a few tens of nanoseconds, the ALU function select should settle on the correct function output = A. So B (data bus) theoretically shouldn’t matter, but what if it does? The 74181 is just a big collection of ANDs and ORs. The value of B may be logically irrelevant, but can it still cause problems if it’s not a valid voltage? For example the expression (X and Y) OR (X and /Y) is logically independent of Y, but if you actually build that circuit and feed it 2.5v for Y, I bet it won’t work properly.
The ALU sees an invalid voltage at one of the B inputs, so it generates an invalid voltage at its output, which eventually makes its way back to the input, creating a feedback cycle of badness. It doesn’t end until the ALU bus driver is disabled.
I’m not sure how plausible this theory is. It doesn’t fit with my previous discoveries, like replacing the HCT377 with a LS377, other than that those changes would cause small changes in power usage, noise, or timing that might affect this condition.
I’m not sure what tests I can do to confirm or deny this theory. Hmmm…
Thinking about it further, I believe the combinatorial loop explanation is correct. You can’t feed invalid inputs to a chip and expect valid outputs, even if the values of those inputs shouldn’t matter. It would be similar to setting a ROM’s address input to 101x, where A0 was 2.5v, and expecting a valid output because addresses 1010 and 1011 happened to hold the same value.
Not so sure if your theory works (or I’m missing something). The B feedback goes thru a ‘241 – driver right? In this case, it will, when driving, the renormalize the values. After all, it isn’t an analogue switch, but a driver. So maybe some noise on B but it will stabilize very quick once the ALU function code is steady. So with a stable function code and stable A (due registered nature) and stable voltages on B (due driver), there can’t be any glitches far from a cycles start.
Since the RAM is transparent until CE or WE goes away, we looking for timing issues at the END of a write cycle.
I could be wrong, as I have been many times before! 🙂 But there are definitely invalid voltages coming from the ALU output, which last for the entire clock cycle. So something is going wrong well before the end of the write cycle.
Hi Steve. Like Hans, I wanna know whether a lower clock rate cures the problem.
My own theory is that, during the write to memory, the bad data on the ALU output is simply a reproduction of bad data on the left-hand ALU input — IOW, bad data on the output of the Accumulator. And THAT is data from the PREVIOUS CYCLE.
I’m thinkin there could be a violation of data setup time in the previous cycle (the addi). Ie; the ‘173 (Accumulator) inputs have new data presented (or not! — see below), and then — too shortly thereafter — the ‘173 receives its clock pulse. The new data levels cannot be reliably captured because the signals are still in transition at the critical moment. The result is a metastability “hangover” affecting the following cycle: ie, one or more ‘173 output signals which hover between zero and one, taking an excessive amount of time to resolve. (Your scope shot seems to show this, albeit with the hovering in the 2.5V range misleadingly quantized and presented as rail-to-rail voltage swings. It does seem odd that the metastability fails to resolve quickly, and instead persists all throughout the following cycle, but hey.)
It seems significant that the instruction addi#0 (as opposed to addi#15) fails to produce transitions on the ALU outputs (aka ‘173 inputs). You & I discussed this privately by email. Maybe that explains why addi#0 seems to sidestep the problem. Adding zero is a NOP, and this means no transitions at the critical moment on the ‘173 inputs.
Hope this makes sense, and I’m not missing the context somehow. Please report whether a lower clock rate helps!
— Jeff
FYI, a 1.25 MHz clock (the slowest I had handy) made the problem less frequent, but it still happened. But this mystery has now been solved (I hope!), see http://www.bigmessowires.com/2013/09/21/sneaky-combinatorial-feedback-bugs/