

Apple II Copy Protection

Growing up during the heyday of Apple II computers, I learned about something mysterious called copy-protection. This meant floppy disks could be used to run software, but the software couldn’t be copied to other floppy disks. As a 10-year-old nerd, this left me confused. Running a game or other piece of software required reading the data from the disk. Copying the disk required reading that same data, then writing it back to another disk. How could it be possible for a floppy to be readable when running a program, but not readable when copying the program? It didn’t seem to make sense.
Years later I learned more about copy-protection, and my experiments with Floppy Emu have also provided insights into floppy-specific copy protection methods. It’s fascinating stuff, so let’s look at it! We’ll begin by examining how Apple II floppy disk access works in the normal case, then we’ll see some of the abnormal tricks that were used to implement copy protection. We’ll also look at how floppy access on the original Macintosh differed from the Apple II, and how this affected copy protection.
Floppy Fundamentals and Limitations
A floppy disk is a wheel-shaped disc of magnetic media with a hole in the center. The data is stored in a series of concentric circles, called tracks. Unlike the single spiral groove on a phonograph record, each track on a floppy disk loops back onto itself, and does not intersect or overlap the other tracks. The disk spins continuously with a constant speed and direction, while a stepper motor moves the read/write head inward and outward as needed. To access a specific piece of data, the head must step in/out until it’s over the correct track. To find the desired information, the computer then begins reading data from the track, starting with whatever portion of the track happened to be passing under the head at that moment. It keeps reading until it recognizes a marker for the desired information, then it reads the information itself immediately afterward. The access time is the sum of the time needed to position the head over the proper track plus the time needed to wait until the desired data passes under the head (on average, half a rotation of the disk).

On an Apple II floppy disk, a track is just a circular buffer of about 50,000 bits, with nothing to mark its beginning or end. Even the boundary between one byte and the next is unknown, so framing the bitstream into bytes correctly requires additional work. The disk controller must rely on the first fundamental rule of Apple floppy disks: the most significant bit of a disk byte must always be 1. If at any time the disk controller reads a byte whose MSB is not 1, then the byte framing must be wrong. Adjust the framing by one bit, and try again.
The disk controller must also honor the second fundamental rule of Apple floppy disks: a disk byte may contain no more than two consecutive zero bits. While the first rule is an arbitrary choice to make framing easier, the second rule is a physical limitation imposed by the way data is encoded magnetically. A 1 bit is stored as a reversal of the magnetic polarity on a region of the disk, while a 0 bit is stored as no reversal of magnetic polarity in that region. With too many consecutive zero bits, you’ll get too large of an area with no magnetic reversals. I’m unsure exactly what problem this leads to – the magnetic field in that region becomes too weak, or the read circuitry loses synchronization maybe – but the end result is that it’s forbidden to have more than two consecutive zeroes.
GCR Encoding
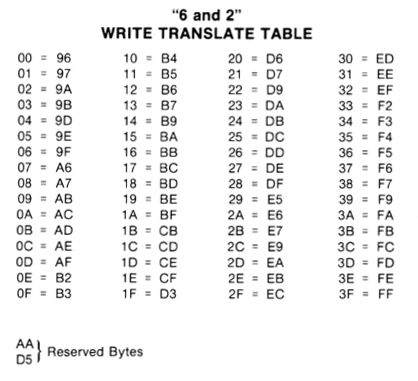
But wait a minute: if the MSB must always be 1, and consecutive zeroes are limited to two, that rules out more than half of all possible byte values. How can you store arbitrary data on a floppy disk, if more than half the possible byte values are forbidden? The answer is that program data and files aren’t stored directly on the floppy disk. Instead, their bytes are encoded in a process that converts logical bytes to disk bytes. On the Apple II, this process is called 6-and-2 Group Code Recording, or just GCR for short. There are 66 possible byte values that satisfy fundamental rules 1 and 2. Setting aside two of these as reserved, this leaves 64 possible disk byte values: enough to encode 6 bits of logical data with a lookup table, because 2 ^ 6 = 64. This means that every three bytes of logical data (24 bits total) will be stored on the floppy disk as four bytes of disk data (one of 64 possible values per byte, so 6 bits per byte, 24 bits total). Thus, data undergoes an expansion of 33% in size when it’s stored on a floppy disk.
Sectors
By itself, the GCR encoding scheme isn’t enough to build a working floppy-based file system. We also need some way to identify where a track begins, and where specific pieces of data lie within a track. On the Apple II, a track is divided into 16 sectors, with 256 bytes of logical data per sector (342 actual disk bytes due to the 33% GCR overhead). The start of each sector is marked with the magic byte sequence D5 AA 96. Because two of those magic bytes are the two reserved values that meet rules 1 and 2 but aren’t used for GCR, this sequence is guaranteed never to occur in the middle of other encoded data. After this sequence lies a few other bytes of header data: the sector number, track number, etc, and then (glossing over some details) the sector data itself. After the sector data, there’s a checksum and another magic sequence to mark the end of the sector.
It’s important to realize that sectors are just arrangements of data in a track. There’s no physical boundary that separates them, and nothing special about them except that they’re regions of data marked with certain magic bytes. Normally the last byte of a sector is not followed by the first byte of the next sector, but instead, there’s a series of so-called self-sync bytes between them. The sync bytes don’t contain any information, but they’re organized in a way that takes advantage of fundamental rule #1: the MSB of a disk byte must always be 1. No matter where the disk controller begins reading and framing bytes in the middle of a series of sync bytes, it will always end up with the correct byte framing after reading at most 5 sync bytes. So a standard floppy disk will always have at least 5 sync bytes between the bytes of two consecutive sectors.
If you search the web for illustrations of a floppy disk’s tracks and sectors, you’ll find lots of diagrams like this:
That diagram is misleading in several respects. On a real floppy disk, the sectors in each track aren’t aligned with those in the neighboring tracks, but instead each track is staggered from the next by some random amount. Sectors in the same track aren’t immediately adjacent to each other either – there’s actually a small gap between one sector and the next. Nor are tracks truly adjacent to each other. A real floppy has unused space between one track and the next outer and inner tracks. Here’s a better diagram of a hypothetical three-track floppy disk, showing the stagger offset between sectors in adjacent tracks, the inter-sector gap, and the space between tracks:

Booting from Floppy
When you insert a floppy disk, and reset the Apple II or type PR#6, a small piece of code is run from the disk controller’s ROM. This code knows how to step the head to track 0, look for D5 AA 96, and examine sector headers to find sector 0. Once it finds it, it loads 256 bytes of data from sector 0 into memory, assumes that this data is executable code, and runs it. What happens after that depends on the software, and the code that was loaded from sector 0. Normally this bootstrap code will load additional code and data from other sectors on the disk, until the whole program is loaded and ready to run.
Copying a Floppy (or not)
A simple disk copy program assumes that the floppy being copied is organized in the standard way: 35 tracks, 16 sectors per track, 256 bytes per sector, with a particular checksum algorithm, and D5 AA 96 marking the start of each sector. It attempts to read the data from each sector into memory, then it writes the same data out to a new floppy disk. If anything goes wrong during reading the sectors from the original disk, the copy process will fail.
The crux of copy-protection is this: the bootstrap code loaded from sector 0 has total control over the floppy disk drive and the way the data in other sectors is encoded. Only sector 0 must be encoded and stored in the normal way, so that the initial ROM routine can load it. Thereafter, the software’s bootstrap code has no obligation to follow the standard conventions for track layout, GCR encoding, sector marker magic sequences, or anything else. In fact, pretty much everything is up for grabs.
When this sector 0 bootstrap code is running with the original floppy disk, it knows how to find and load data from the other sectors, using whatever tricky mechanisms the developers used to tweak the standard organization of a floppy disk. But when a disk copying program is running, it sees sector 0 as just part of the data to be copied, and it attempts to copy all the other sectors using the standard methods too. If the copy-protection is good, this attempt will fail, because a sector checksum somewhere will appear invalid, or a sector can’t be found on the track where it was expected, or some other similar problem. Or in some cases the copying will appear to succeed, but then the copied disk won’t work.
The art of cracking copy-protected software involves examining the code stored in sector 0, and analyzing it to understand how it works. With persistence, this will reveal what tricks were used to obfuscate the data in the other sectors. The cracker can then deobfuscate the data, and create a new non-protected floppy disk using the standard disk methods.
Data Tweaks
The easiest way to defeat a simple disk copy program is to alter the sector data in some way that’s consistent, but different from the standard.
Magic Bytes: Who says D5 AA 96 must mark the start of a sector? A copy protected disk might use D5 D5 96, or some other sequence that works just as well, assuming you’re looking for it. But a simple disk copy program will only be looking for D5 AA 96, so it will never find the start of those sectors. It will appear as if the disk is empty.
Checksums: Each Apple II sector is checksummed using a simple algorithm. (See the book Beneath Apple II DOS if you’re curious.) But there’s nothing magic about that algorithm, and a copy protected disk might use another. To the sector 0 bootstrap code, this would be no problem as long as it knew how to compute the new checksum. But to a disk copy program, it would appear as if every sector had a checksum error, and the disk was corrupted.
Bad Sectors: A bad sector that was never intended to be read might be intentionally placed on the original floppy. The program code would know to ignore this sector and not even try to read it, but a disk copy program would try to copy it, and fail.
Duplicate Sectors: Multiple copies of the same sector might be placed in a track, with each copy offset by 90 or 180 degrees along the track’s circumference. These duplicate sectors would contain different contents. Depending on where the head was located within the track when the computer began looking for the sector, it might read any of the copies. On the original floppy disk, repeated reads of that sector would therefore appear to return different results. But a copy of the original disk would contain only one instance of the sector, and so would always return the same result. The bootstrap code could use this difference in behavior to detect whether the floppy were original or a copy.
Sector Size: How about 512 bytes per sector instead of 256? To a standard disk copy program, it would be unintelligible.
More: Offset the sector numbers by some constant delta, insert a pad byte somewhere, disguise the headers with an XOR trick…
Hidden Data
Normally the bytes between the end of one sector and the start of the next are just self-sync bytes. But what if you stored a magic byte sequence in there, and added a routine to the bootstrap code to verify it’s there? A standard disk copy program will only copy the contents of the sectors, and not the apparently useless sync bytes between the sectors. So the copy will appear to succeed, but the copied disk won’t run correctly because the check for the magic byte sequence will fail.
Encoding Tweaks
GCR uses a standard lookup table to convert six bits of logical data into a disk byte, and also to do the reverse translation. But who says a copy-protected program has to use the standard GCR table? Or for that matter, who says it has to use GCR at all? A clever copy-protection designer could use any method he wanted to encode logical bytes as disk bytes, as long as rules 1 and 2 are still satisfied. But a different encoding method from the standard would be unintelligible to most disk copy programs.
Track Hacks
There are 35 tracks on a standard Apple II floppy disk: 35 concentric circles that store data. But the positions and radii of these circles are arbitrary, and there’s no physical track structure on the disk media. Instead, the media is just one continuous piece of magnetic material. Tracks are packed as close to each other as possible, up to the limit where the magnetic field of one track would interfere with its neighbors if they were any closer. An interesting detail: the stepper motor that moves the drive head has a 4x higher resolution than the distance between tracks. It takes four steps of the head to move from one data track to the next. So on a standard floppy disk, if the head is on track 0, it must go step-step-step-step to reach track 1, then step-step-step-step to reach track 2, etc.
So what happens if you’re at track 1, and the drive goes step-step? Where is the head now? It’s on a region of the floppy disk halfway between where track 1 and track 2 are normally stored, which we’ll call track 1.5. You can’t store any data at track 1.5 without interfering with data in track 1 and track 2, because they’re too close together. But a clever copy-protection author can sacrifice a little bit of disk capacity in order to store hidden data in these intermediate non-integer numbered tracks. For example, there might be data on tracks 1, 2, 3, 4.5, 6, 7, 8 etc. A standard disk copy program would see no data on tracks 4 and 5 where it expected it, and it would overlook track 4.5 entirely. Sneaky! The same technique can also be used to make quarter tracks, like track 3.25.
Half and quarter tracks could also be used to measure position dependencies between data in adjacent tracks. For example, during mastering of the original disk, the drive might write a few sectors to track 1, then step to track 1.25 and immediately write more. As long as the track 1.25 sectors didn’t occupy the same part of the track perimeter as the track 1.0 sectors, there would be no magnetic interference. When running the software, the bootstrap routine could read the sectors from track 1, then step to 1.25 immediately after the last sector, and verify that the next thing on track 1.25 was the expected additional sectors. Even a special disk copying program that could handle quarter tracks would have trouble with this, because the relative positions of sectors in tracks 1.0 and 1.25 would not be preserved in the copied disk.
You Big Cheater!

Many Apple II games appeared to copy successfully, but if you ran the copy, you would eventually reach some kind of roadblock complaining “you stole this game!” or otherwise chastising you for making a copy. It’s not hard to see how this might have been done. If we assume the game’s critical initialization code is in sector 1, there might be two copies of sector 1 on the original floppy disk. The real version might have a non-standard sector marker like D5 D5 96, and the decoy version would have the standard sector marker D5 AA 96. A standard disk copy program would copy the decoy version of sector 1 and ignore the real version. If the decoy version contained code to display a “you big cheater” message, it would be displayed when you attempted to run the game from the copied disk.
Macintosh Copy Protection
Although the original Macintosh used a different size and capacity of floppy disk than the Apple II, it still employed a very similar sector structure, with the same GCR encoding method and D5 AA 96 magic sequence to mark the beginning of each sector. In theory, the same types of copy protection tricks used on the Apple II could also have been used on the Macintosh, but in practice relatively few Macintosh programs were copy protected.
Strike 1 against Macintosh floppy-based copy protection: The floppy disk drive on the Macintosh was not capable of quarter or half stepping. This ruled out all the sneaky fractional track methods of copy protection.
Strike 2: The API routines that were used to read and write data from a floppy were considerably more complex on the Mac than the Apple II, and unlike the Apple II, their source code listings were not published. The Mac floppy I/O routines were also asynchronous, designed to run simultaneously with other activity on the mouse, keyboard, or serial port. Embedded in these routines were all the assumptions about D5 AA 96, checksums, sector sizes, and so forth. It would have been possible for a program to bypass all these routines and access the floppy controller (IWM chip) directly, and do the same kind of data or encoding tweaks that were common on the Apple II. But the complexity of the task and the difficulty of multitasking floppy access with mouse and serial port meant that few developers attempted it.
Strike 3: Two years after the introduction of the Macintosh, SCSI hard disks were introduced, and customers began to expect that all software would be installed to their hard disk rather than running directly from the floppy. A program that used floppy-based copy protection would make that impossible, angering customers and hurting sales.

Story Time!
Did you ever work on a copy protection system on the Apple II or another vintage computer system, either as the copy protection developer, or as a cracker? Did I overlook any especially sneaky methods of copy protection, or botch my explanation somewhere? Please leave a note in the comments below, let’s hear your story!
Read 32 comments and join the conversation32 Comments so far
Leave a reply. For customer support issues, please use the Customer Support link instead of writing comments.
Complexity didn’t stop Macintosh software from being copy protected though. Microsoft Multiplan was one of them, it even included a backup copy just in case your original failed!
Also, there was 3.5″ protection used with Apple IIgs programs, but like the Mac, it wasn’t as sophisticated. Another interesting footnote was Unidisk 3.5″ drive specific copy protection. One program used it that I know of, Quark Catalyst. In that case, custom disk reading routines were uploaded to the Unidisk 3.5’s onboard controller RAM to run the IWM directly for reading the copy protected disks. It was VERY effective as that program wasn’t cracked until recently.
This is why Apple’s tech docs for the IIc and IIgs discouraged any protection on 3.5″ disks since protection that specific would fail if you used a newer drive.
Great write-up. I suspected stuffing data between tracks was the method being used. Nice to see all of the other methods and get down to how copy protection worked.
Thanks for taking the time to write it up. And thank you for FloppyEmu, I love mine.
One method I always thought was elegant involved the software vendor using a laser to ablate a specific physical spot (barely discernible to the naked eye) on the media surface; if the verification routines were able to write to that spot without errors, then it knew it was a copy and not the original disk.
Part of Woz’s hardware simplification was to ignore the index hole, which is why the sectors are randomly shifted from one sector to the next on the Apple. This made making flippies (disks that you could flip over so that you could use both sides in drives that only handled one side) for the Apple incredibly easy; you only had to punch another notch for a second write-protect tab, but could ignore punching holes (in the outer jacket of the disk only and not the disk itself) needed to expose the index hole when the disk was flipped.
For systems that did use the index hole, you could get physically different types of disks. “Soft sector” disks had a single index hole that marked the beginning of the track. “Hard sector” disks had multiple index holes, each marking the beginning of a sector. In these cases, you normally do end up with the sector data unshifted (or only small shifts) from one track to the next.
TRS-80 systems were designed to use soft sector disk, with a single index hole. As a low-tech alternative to the laser created defects that Jeff mentioned above, you could punch a second index hole (in the disk itself unlike the process for making flippies where you are only punching the jacket). If this extra index hole was positioned at an angle that was inside an already recorded sector, it would make the disk controller give an error when reading/writing that sector because it now appears that the track ended in the middle of a sector.
There is typically some filler in between sectors, both to give software some breathing room as well as so that variances in timing from one system to the next don’t allow accidentally overwriting the beginning of the next sector when rewriting the one before. But if you plan on using the disk as read-only, you can tighten up the sectors and fit an extra sector per track. I’ve seen this on IBM PC format disks, which use MFM rather than GCR encoding, and I think they are also taking advantage that MFM encoded sectors are variable size (it depends on the actual data). With fixed data, they don’t have to reserved space for the worst-case encoding, but only the space needed for that particular data, which again allows reducing the inter-sector filler.
I’ve never encountered a hard-sectored 5 1/4 floppy disk. Do you know what computer systems used them? As for index holes on floppy disks, my vague recollection is that only IBM computers used them, and Apple, Atari, Commodore, and others of the era didn’t. From what you’ve said, TRS-80 was also in the index hole camp. I can’t seem to find a definite list, though.
Yeah, it’s interesting how much space is “wasted” on a standard floppy disk, and the tricks used to cram more data in there at the expense of rewritability or reliability. The Apple II floppy writes one bit every 4 microseconds, and spins at 300 RPM which is 200 milliseconds per rotation. That means you should be able fit 50,000 bits per rotation on a single track, times 35 tracks is 1.75 million bits or about 219 kilobytes. Yet a formatted Apple II disk only has a capacity of 140 KB. The rest is lost to the sector headers, footers, checksums, inter-sector sync bytes, and GCR overhead.
I don’t believe MFM sectors are variable size – at least high density MFM sectors for normal PC and Mac floppies aren’t. Maybe standard density MFM sectors work differently? Or are variable-size sectors one of the non-standard tricks that were used for some read-only disks?
The Disk II was quite a bit more raw and hackable in regards to disk formatting and control over the PC/MFM. You could write spiral tracks if you wanted to! Loads really fast and was an effective form of copy protection.
https://en.wikipedia.org/wiki/Spiradisc
The “burning a hole for a bad sector trick” was rarely used due to expense. You had to have something REALLY expensive to protect with that. Even then Central Point released an Enhanced Option Board for PCs to simulate bad sectors to crack that form of protection.
The only machines I have seen reference to hard sector floppies are early CP/M machines, particularly S100 bus era.
Here’s a growing list of some nice walkthroughs on how to circumvent some of the copy protection schemes:
https://archive.org/details/apple_ii_library_4am
Those are some fascinating write-ups on each game’s copy protection! I was vaguely aware of what 4AM is doing, but hadn’t seen that before. I took a look at the write-ups for Frogger, Spy Hunter, and Donkey Kong (all of which work on the Floppy Emu with the right NIB file). They all use non-standard magic bytes for the sector epilogue and prologue, replacing the normal D5 AA 96. One of them also incorporates an intentionally bad sector, then checks to verify it can’t be read. And one (Frogger) also dedicates an entire track to some kind of special disk byte pattern which does not contain any sectors, but which is verified by the game’s code.
You’ll find a whole other set of write-ups at HackZApple (http://www.hackzapple.com/phpBB2) and on my site (http://pferrie.host22.com/misc/appleii.htm). You can read data after turning off the drive, change the contents of the nibble table, measure the distance between two sectors on a track, etc. So many options, you could write a book about them.
Nice article!
I wrote a disk de-protection program in 1985 called DISUN (disk unlocker), and in 1987-1990 wrote //e & //GS games which used copy protection. A few comments:
> If at any time the disk controller reads a byte whose MSB is not 1, then the byte framing must be wrong. Adjust the framing by one bit, and try again.
The controller reads a bitstream rather than bytes. It’s the CPU that is looking for a 1 MSB on the read latch. The controller doesn’t look for framing or try again. What the controller will do is shift a 0 bit into the read latch if it doesn’t see a 1 within a single-bit-time-window, and then it will shift a 1 bit into the read latch if too much time has gone by (ie, no more than 2 zeroes in a row). Because the disk rotation speed varies from drive to drive, the controller has to ‘guess’ how long to wait before it inserts a zero. It also has to put a 1 in eventually or the CPU could be locked up waiting for a 1 MSB on a blank disk with no 1 bits written to it.
> There are 66 possible byte values that satisfy fundamental rules 1 and 2.
There are 85 possible nibble values which have the high bit set and have no more than 2 consecutive zero bits. For ease of encoding/decoding, 64 disk nibbles are used for data encoding.
> On the Apple II, a track is divided into 16 sectors, with 256 bytes of logical data per sector
This is true for 5.25″. 3.5″ drives have 80 tracks in 5 speed zone with 16 tracks per zone. Each track has between 8x (inner) to 12x (outer trk) sectors with 512 bytes per sector.
> The start of each sector is marked with the magic byte sequence D5 AA 96. Because two of those magic bytes are the two reserved values that meet rules 1 and 2 but aren’t used for GCR, this sequence is guaranteed never to occur in the middle of other encoded data.
D5 & AA can be read in the middle of a data sector if the read latch is at a different byte-alignment than how the data was written. This is why 10-bit self-sync $FF bytes are used to force the read latch to the same byte alignment that was used when the data was written.
More to follow…
> Here’s a better diagram of a hypothetical three-track floppy disk, showing the stagger offset between sectors in adjacent tracks, the inter-sector gap, and the space between tracks:
Ideally, this diagram would show the ‘big gap’ of 10-bit $FF sync bytes which marks the boundary between the first and last sector written to the track during formatting and contains the ‘splice point’ of the track. The sectors are not equally spaced around a track.
@ChrisM
> Also, there was 3.5″ protection used with Apple IIgs programs, but like the Mac, it wasn’t as sophisticated.
Tomahawk GS in 1988 stored 924k per disk and wrote consecutive 0 bytes into the large gap which the controller read back as random values. It also streamed compressed stereo digital audio off the 3.5″ on the fly and played it through the ensoniq sound chip.
Rastan GS also used float-byte protection, but could be hard-drive installed. It also supported running from a platinum 3.5″ drive with the protection check being done via the GS IWM, or it would detect that it was running on a white Unidisk and download a special 6502 ‘protection check’ driver into the unidisk’s onboard RAM to check for float-byte protection in the large gap.
Here is a great writeup by 4am of the Datasoft protection used on Mr. Do!, which I also used on my first game at Datasoft, Tomahawk //e.
https://ia801500.us.archive.org/19/items/MrDo4amCrack/Mr.%20Do%20(4am%20crack).txt
Hope that helps fill in some details.
-JB
>There are 85 possible nibble values which have the high bit set and have no more than 2 consecutive zero bits
But there is a maximum of one pair of zero bits, reducing the possibilies to only 72.
> But there is a maximum of one pair of zero bits, reducing the possibilies to only 72.
This is by convention as far as I can tell. My custom GS 3.5″ formats have used all 85. I’ve even tried using 3 zero bits & ECC strategies, but bit injection makes it too hard to recover from errors.
>This is by convention as far as I can tell
That’s interesting. I’m working on an article and just before I read this, I wrote “Note that convention is a powerful force”. The context was the “fixed” order of values in the denibblisation table. 🙂
I see you are correct about the MFM encoding being fixed size; from the description I read long ago in which the clock bit was only inserted between certain bit combinations instead of between every data bit as in FM encoding I was thinking the overall sector size would change depending on the number of clock bits needed. Something to learn every day.
I’m not sure what the hard sector disks were intended for. I bought a few in 1979 not realizing the significance at the time. They worked great on the Apple II, but totally choked the TRS-80.
I would expect all the systems that use the FD1771 and it variants to use the index hole. Wikipedia has a list, but to avoid the spam filter I won’t leave the link.
Thanks for the corrections, JBrooks! I think I’m missing something regarding the byte framing, then. If the disk controller is just a simple shift register, and it’s the CPU that must check for the 1 bit in the MSB, when does the shift register get cleared? If the disk contained the bytes 11010101 11010101, what prevents the CPU from reading 11010101 immediately followed by 10101011? I.e. the bit stream shifted one position, after the first byte is read and the shift register shifts the data again.
I should have said there were 66 disk byte values used by standard 5.25 inch GCR-encoded Apple II floppies, not 66 total possible values. In theory, it should be possible to get a more efficient encoding of the data by using *all* the possible values (85 or 72 or whatever it is), reducing that 33% overhead somewhat. I remember reading somewhere that Woz considered this, but decided it was much too complicated and impossible to do it fast enough on the CPU. Which makes sense – instead of just masking and shifting bits, an encoding scheme using 72 or 85 values would have to do lots of division and modulus operations. How did your custom GS format for 3.5 inch disks handle it?
Do you (or anyone) know the reason for the two consecutive zeroes limitation? As I mentioned in the text, I’ve never really understood that. Somehow it causes data to be read incorrectly, but why? Is it a limitation of the disk controller, or (as I think) a limitation of the magnetic recording media?
> when does the shift register get cleared?
It gets cleared when the CPU reads the latch with the high bit set. On the GS with the IWM in async mode, the latch will hold 8 bits while reading another 8 bits, givng the CPU a 2-nibble read buffer.
This is why the CPU code loops until the high bit of th latch is set, it makes the cpu wait while bits from the head are shifted in from low to high until 8 bits have arrived.
> How did your custom GS format for 3.5 inch disks handle it?
I use all 85 valid encodings to get 6.3 data bits per disk nibble. The encoding method stores 19 data bits every 24 disk bits. The higher density encoding, combined with variable-sized sectors and minimal sync byte overhead results in about 1000k per 3.5″ disk. The 6.3 decoding is more complex than 6 bit encoding, but the 65816 is fast enough to decode it and calculate a shift/add checksum on the fly during read.
> Do you (or anyone) know the reason for the two consecutive zeroes limitation?
Yes, the reason for the 0-bit limit is that a 0 bit is not detectable by the read head, so it’s generated by in internal clock in the controller. If there hasn’t been a 1 bit within the 4us time window, then the controller assumes there must be a zero bit there. However, the CPU clock will vary from CPU to CPU, and the drive motor speed will vary from drive to drive, so the controller can only correctly guess at so many ‘0’ bits in a row before clock drift between the CPU & drive will cause the controller to guess too few or too many 0 bits. This timing drift is slow enough that two 0 bits can be correctly guessed before a 1 clock/data bit needs to come in and re-sync the timing between the controller & drive.
BTW: I suspect that the GS may be able to decode 6.9 bits per 8 disk bits (126 valid encodings), but both the encoding and decoding are complex so I haven’t gotten around to testing it.
-JB
I can see how to increase density using variable sector lengths. Read 3 nibbles to buffer, plus one more for each value EC or greater, and then read 1 nibble to the “extra bits” array (which is now a collection of 1- and 2-bit values, depending on what’s being decoded), but the gain is really small. I also count only 81 values that don’t violate the 3-zeroes rule, not 85.
I’d like to know more about the 6.3 encoding.
> I can see how to increase density using variable sector lengths
The variable sector length is to reduce the number of wasted bits in each track due to rounding to integer # of sectors. On 3.5 with 512 byte sectors, this rounding wastes more track bits than the 256 byte sector size on 5.25. Also speed and track size vary on 3.5.
> Read 3 nibbles to buffer, plus one more for each value EC or greater,
The encoding I use is 16+3 data bits every 24 track bits. The byte-alignment point is 38 data bytes every 48 disk nibbles, but I allow sector sizes which are not byte aligned.
> I also count only 81 values that don’t violate the 3-zeroes rule, not 85.
Sorry, I crossed wires with the hex version. Yes, it’s $51 valid disk nibbles, 81 decimal. Since there are no reserved nibble values, reading headers and establishing correct byte framing is tricky.
The gain is about 105.5% using 81 nibbles. I estimate that optimal density while maintaining the <3 consec 0-bits rule is 116% of 6&2 encoding, by using 126 nibbles. But I haven't tested that yet.
-JB
My idea favours the nibbles 40-4F, since there’s room for only 1 bit to be shifted in, so 6×1-bits could be stored in the space that would normally contain the 3×2-bits, and it uses only 80 out of 81, so the spare value can be duplicated for an ID.
Apple II Disk Copy Protection
In 1981/1982, I had a 50/50 business partner who provided me with an Apple II. I spent a year of nights and weekends producing a Pert Chart system unlike anything done before. (My partner showed it to Apple and, instead of buying it, produced MacProject – based on it near as I can tell…)
Anyway, after I had essentially completed the project, my partner married a woman who had just gotten an MBA from Harvard. They secretly incorporated in Delaware then sent me an agreement to sign offering me 10% of the profits of the corporation. I was not to be part of the corporation. As everyone knows, businesses do not have to make profits in order to make the business owners rich. I saw this as a blatant attempt to steal all my work.
2000 byte limit on comments on this site? Wimpy… 🙂
…
Get the rest of the information here if you are interested:
http://www.astroshow.com/papers/AppleII.doc
…
As agreed, I sent the disks containing the most recent version of the executable to my partner. I never heard from him again. He had moved to the MIT area by then and I have always envisioned him going from super-hacker to super-hacker at MIT begging them to crack the copy-protection scheme. I am quite sure no one ever was able to beat it.
It was a perfect, unbeatable copy-protection scheme. At least with respect to the Apple II. I know that there is no way to write a truly unbeatable copy-protection scheme but this scheme did not provide ANY obvious clues as to what was going on…
I still have the Apple II and all the books, programs, and documents I bought at the time. The machine is a “Bell and Howell” machine so apparently not worth as much as a “real” Apple II although I would have thought that rarity of this item would have made it MORE valuable.
I will consider any reasonable offer if anyone is interested. 🙂
Thanks,
Howard
One of the things that made Steve Wozniak a legend was the clarity and minimalism of his designs. The Disc ][ controller does as little as possible in hardware, which is why it only has a few chips, and offloads all the difficult stuff to software. And his firmware code is clean, optimal, and easy to grasp. Reading his code was inspirational.
In my Apple II (][+ and //e) days I used to use a Disk II drive that had an intentional twist in the drive belt for the spindle. Written disks were recorded backwards and could ONLY be read on that drive. They appeared as gibberish on other drives. Yes a disk can be formatted and written to with the spindle driven in either direction!
Howard,
As it turns out, you were not the only one to create the “Perfect Track” copy protection scheme in the 80’s 🙂 Somewhere around here I still have the source code to code to create perfect tracks (including as an otherwise normal DOS 3.3 track), as well as the verifier …. and … the bit copier code to copy such tracks, which can be identified by looking for “random” nibbles (requires multiple reads of a track). If none are found, then the track can be assumed to be a perfect track, and with special write routines copied. (Identification and write are sensitive, and in theory could require parameter changes to make everything work, but we could only try with out examples as we never found such a protection in the wild).
If you still have the source, would be great if you shared it 🙂
I forgot to mention that this is covered, briefly, in Chapter 5 of Tome of Copy Protection, as Version 2 of the fourteen works of art. Source code included.
Thanks for an interesting writeup. For a comparison with non-apple encoding schemes you may want to look at the website I linked here https://extrapages.de/archives/20190102-Floppy-notes.html
I used to crack Apple II games with zero knowledge of the disk encoding. I would write a short routine to read track zero sector zero, because that was always readable. Then I would use the disassembler to examine the loop logic of the boot sector and find the jump instruction that branched out of the boot sector. Then I would replace that jump instruction with a break instruction.
Next I would use the G monitor command to start running the boot block code. When I got back to the monitor (when my inserted break instruction was executed), I would examine memory to see what the boot block had loaded. Usually it would have loaded the rest of track zero, and that would contain the rest of the program loading code. Once again I would use the disassembler to search for a jump instruction that branched out of the program loading code and replace that with a break instruction. Then I would use G to execute the *second stage* of the program loader. Usually this would finish loading the game, turn off the disk drive and return to the monitor with the entire game loaded into memory, ready to run.
Finally, I would use the G command to jump to the address I had replaced with the break. If I was successful, the game would then start up with no further disk activity.
The next step was to reboot and do it all over again, but instead of branching to start the game, I would instead examine memory to find all of the areas of memory that had been modified by the boot sequence. I would then copy all those areas to the high resolution page, boot into DOS and BSAVE those areas. The last step was to write a short assembler program that would consist of an unpacking routine, followed by all the game data.
This reduced the game to a single file that could be run with BRUN that was minimal in size, only containing the necessary program data. This worked almost every time for the type of game that would load completely from disk at boot time, then never access the disk again.
One more nifty trick —
Sometimes the copy protection system would be implemented as a standard or lightly modified DOS with a replacement RWTS routine. This was often the case with games that accessed the disk during gameplay. If this was the case, and I could find the RWTS routine, I could copy the RWTS routine to the high res graphics area, reboot to standard DOS, or sometimes DOS 3.2, then copy the copy-protected RWTS routine back to its correct place. This would often let me catalog the copy protected disk and bload programs. Often it would even let me format new copy protected disks with the standard DOS but the copy protected RWTS! I had a floppy full of “trophy” RWTS routines I had captured from games. I could use those captured RWTS routines to create my own copy protected disks. There was a way to use the DEMUFFIN program sometimes to flat-out copy an entire disk sector by sector to a normal floppy, then replace the copy protected RWTS with a standard RWTS, thus turning the copy protected disk into a disk that could be copied conventionally.
There were lots of complications the copy protection designers would throw in, such as putting critical data into the text video memory. The idea was that if you hit break, the text page would scroll, and the data would be scrambled. This was something that could be gotten around with a little extra assembler programming.
In short, playing games was fun, but going up against the copy protection designers was a battle of wits, and was often more fun and rewarding than playing the actual game!
Have you heard of RWTS18? It uses 6 x 768 byte sectors per track (the equivalent of 18 x 256 byte sectors), for a total of 157.5K per disk. It was used in Prince of Persia. https://fabiensanglard.net/prince_of_persia/pop_boot.php
Would this work on the Floppy Emu assuming the disk image was in NIB or WOZ format?
Yes, I think that would work.
Beneath Apple Dos says that the hardware can only support at most one run of two zeros (page 3-20, fifth printing). But posts here say that’s really only a convention? I’m asking because even without a more complex encoding, having over 80 distinct values could be used to shorten address fields or have far more “globally unique” markers on a disk? Even 68 values instead of 66 would be useful if it worked on a real Apple 2?
Lane, if you’re wondering why eight years later you sold a copy of the Tome in the UK… yeah, it was me.
Dave, very cool, thanks for the purchase. Hope you find it useful, enjoy!