

Birth of a CPU
I’ve finished the basic guts of the CPLD CPU, and it works! It’s still missing roughly half of the intended CPU functionality, but what’s there now is still a usable CPU. I’ve implemented jumps, conditional branching, set/clear of individual ALU flags, bitwise logical operators, addition, subtraction, compare, and load/store of the accumulator from memory. The logical and mathematical functions support immediate operands (literal byte values) as well as absolute addressing for operands in memory. Not too shabby! Not yet implemented are the X register, indexed addressing, the stack, JSR/RTS, increment, decrement, and shift.
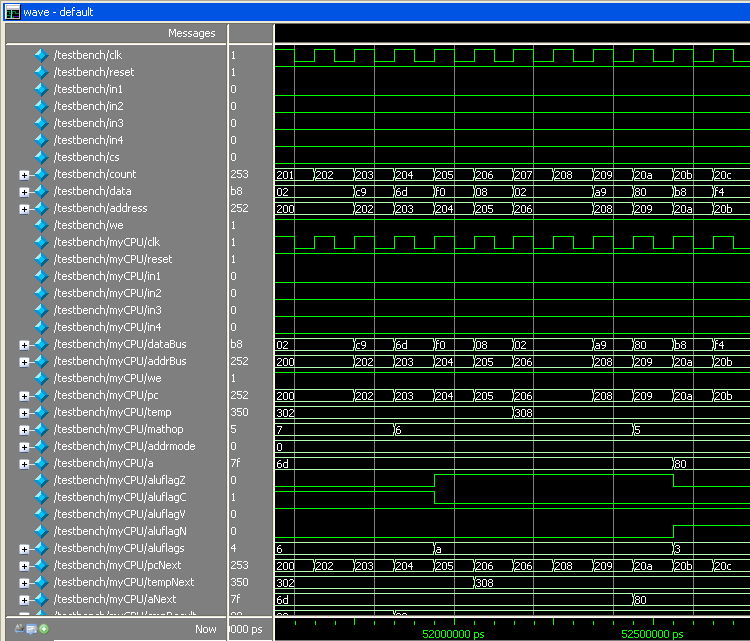
I wrote a verification program to exercise all the instructions in all the supported modes, which I re-run after every design change to make sure I didn’t break anything. Here’s a screenshot of the verification program in ModelSim, which doesn’t really demonstrate anything useful, but looks cool. You can grab my Verilog model, testbench, and verification program here. Comments on my Verilog structure and style are welcome.
Now for the bad news. The design has consumed far more CPLD resources than I’d predicted. I’m targeting a 128 macrocell device, but the half-finished CPU I’ve got now already consumes 132. By the time it’s done, it might be twice that many. While I think my original accounting of macrocells needed for registers and state data was accurate, it looks like I greatly underestimated how many macrocells would be required for random logic. For example, after implementing the add instruction, the macrocell count jumped by 27! That’s almost 25% of the whole device, for a single instruction.
I’m finding it difficult to tell if the current macrocell total is high because I’m implementing a complex CPU, or because I’m implementing a simple CPU in a complex way. Could I get substantial macrocell savings by restructuring some of the Verilog code, without changing the CPU functionally? It’s hard to say, but I think I could. Looking at the RTL Model and Technology Map View is almost useless– they’re just incomprehensible clouds of hundreds of boxes and lines. Yet deciphering these is probably what I need to do, if I want to really understand the hardware being synthesized from my Verilog code, and then look for optimizations.
The Verilog code is written in a high-level manner, specifying the movement of data between CPU registers, but without specifying the logic blocks or busses used to accomplish those movements. These are left to be inferred by the synthesis software. For example, the add, subtract, and compare instructions could conceivably all share a single 8-bit adder. So do they? The Verilog code doesn’t specify, but I think the synthesis software inferred separate adders. On the surface this seems bad, but I learned in my previous experiments that the software is generally smarter than I am about what logic structures to use. Still, I’ll try restructuring that part of the code to make it clear there’s a single shared adder, and see if it helps or hurts.
The core of the code is a state machine, with a long always @* block implementing the combinatorial logic used to determine the next values for each register, each clock cycle. There are 10 unique states. The clever encoding of the 6502’s conditional branching and logic/math opcodes (which I’m following as a guide) allowed me to implement 24 different instructions with just a handful of states.
Verilog NOT Operator, and Order of Operations
I encountered a mystery while working on the CPU design. I attempted to aid the synthesis software by redefining subtraction in terms of addition:
{ carryOut, aNext } = a + ~dataBus + carryIn;
This works because a – b is the same as a + not(b) + 1. If carryIn is 1, then subtraction can be performed with an adder and eight inverters. Fortunately the CPLD already provides the normal and inverted versions of all input signals, so the bitwise NOT is effectively free. I was very surprised to find that the above code does not work! It computes the correct value for aNext, but carryOut is wrong. The following code, however, does work as expected:
{ carryOut, aNext } = a + {~dataBus[7], ~dataBus[6], ~dataBus[5], ~dataBus[4], ~dataBus[3], ~dataBus[2], ~dataBus[1], ~dataBus[0]} + carryIn;
Now how is that second line different from the first? I would have said they were completely equivalent, yet they are not. The difference seems to be some subtlety of Verilog’s rules for sign-extending values of different lengths when performing math with them.
Even stranger, I found that the order in which I listed the three values to be summed made a dramatic difference. Hello, isn’t addition associative? Apparently not, in the bizarro world of Verilog:
{ carryOut, aNext } = a + ~dataBus + carryIn; // design uses 131 macrocells
{ carryOut, aNext } = carryIn + a + ~dataBus; // design uses 151 macrocells
{ carryOut, aNext } = carryIn + ~dataBus + a; // design uses 149 macrocells
Read 8 comments and join the conversation
8 Comments so far
Leave a reply. For customer support issues, please use the Customer Support link instead of writing comments.
If it’s any consolation (and it probably isn’t), your design gets compiled to 96 macrocells using the xilinx tools…
One thing you might try is separate out the different structures into their own “always @*” blocks. This may help the compiler better separate out concerns (do we really care what the ALU is doing when we aren’t in a “doMath” state?)
96 macrocells?? Wow! Targeting what Xilinx device?
Yeah, some amount of simplification is probably in order. I was able to shrink it to 118 by extracting the adders and subtractors used for ADC, SBC, and CMP into a separate alu module. From there I shrank it further to 107 by using the Altera megafunction LPM_ADD_SUB instead of behavioral Verilog to describe the alu operation. I’m not too keen on turning the design into a bunch of megafunction black boxes, though.
Targeting the XC2C128 (coolrunner II, 128 Macrocell – I was just trying to get a comparable device). I would be surprised if the device was significantly different from the Altera part.
I think you’ve discovered the ugly truth about synthesis tools – the performance varies a lot by how you write your code and what toolchain you use. Optimal results requires low-level attention to details. (A project manager I know once said that he’d always budget twice as many fpga resources as was needed for the actual design just to speed up development time).
I’m not too familiar with the Xilinx parts, but I think something from the XC9500 family is probably the closest match, like the XC95108.
If want to implement more operations and still keep the macrocell count down, you might consider a bit serial ALU implementation. You implement the CPU registers with shift registers and have the ALU only process 1 bit at a time. It would be approximately 8 times slower than processing 1 byte at a time, but at the benefit of 1/8th the area.
After lots of logic optimizations, I have the design down to 95 macrocells in the Altera Max 7128, without sacrificing any functionality. I also tried the Xilinx software, and it synthesizes to 90 macrocells in the XC95108 (the most similar device) and 77 macrocells in the more modern Xilinx Coolmax II series (not available in PLCC).
Interesting idea about the bit serial ALU. I think I’d prefer to keep it an 8-bit design, and sacrifice some features instead.
Through more experimentation, I’ve managed to further shrink the design to 85 macrocells. I saved two by removing reset-handling logic from registers that didn’t really need it. Saved one more by trying all the state machine encoding types in the project settings, and selecting the one that gave the smallest size (sequential encoding). But the biggest savings came by changing the “Parallel expander chain maximum length” to 0. That saved 7 more macrocells, although it greatly increased the number of shared expanders used. I need to study the datasheet more to get a better appreciation for what that means. Parallel expanders seem to be an Altera-only feature, while both Xilinx and Altera CPLDs of this generation have shared expanders borrowed from neighboring macrocells.
It’s hard to believe I’ve now gone from 132 to 85 macrocells without any significant changes to the CPU design. I think I’m ready now to go forward with adding more functionality to the CPU. The X register and indexed addressing mode will be next.
1/3 reduction in resources is pretty good.
I’d be nice if you could post the code again, when you get to a good spot – some of us are following along at home…