

Archive for May, 2016
AV2HDMI Video Adapter for Apple II

Many retro computers and game systems have a composite video output – the familiar round yellow plug. Unfortunately, composite video inputs are increasingly rare on modern TVs and computer monitors, creating a headache for retro enthusiasts. This is a mini-review of one solution to this problem: a composite video (and stereo audio) to HDMI converter box called AV2HDMI, which I purchased for $18 from Amazon.com.
Converting composite video to a more modern format is more difficult than it might first appear. It’s not merely a matter of physically converting one plug shape to another. Composite video is an analog signal that combines the color, luminance, and frame synchronization information all on the same wire. It comes in different formats like NTSC, PAL, and SECAM, which imply a different number of horizontal lines per frame and frames per second. The signal is also interlaced, meaning that the even lines are sent in one frame and the odd lines in the next frame.
A converter must detect the input format correctly, separate the color/luminance/sync info, deinterlace the lines, perform analog-to-digital conversion, upscale the resolution, and output a more modern VGA or DVI or HDMI signal. There are plenty of opportunities for things to go wrong and generate a poor quality result. It doesn’t help matters when the original composite video signal doesn’t quite meet the NTSC spec in the first place, as is the case for the Apple II series.
AV2HDMI
The AV2HDMI box that I purchased is one of at least 20 very similar items on Amazon, all with the identical case and connectors, but with different names, colors, and labels. It seems likely that these are all really the same device, with the guts manufactured by a single vendor, and then many other vendors packaging and rebranding it. The case is sealed tight, without any screws or other obvious methods of disassembly, so I couldn’t peek inside to learn more.
Previously I was using the composite video input on a Dell 2001FP LCD monitor, which seems to be known for good handling of composite video. But in an effort to declutter my desk, I really wanted to get my Apple II systems working with the primary Asus monitor that I also use for my PC and Macintosh work. Keeping around the Dell 2001FP just for occasional use was a hassle, so my main motivation in purchasing this converter was convenience rather than top-quality video output. I also wanted something that could work with any Apple II system, as well as old video game systems, rather than a solution that’s specific to any one model of Apple II.
The overall results from the AV2HDMI aren’t quite as good as the 2001FP, but they’re close, so I’m happy. I can’t decide if it’s stretching the 4:3 image to 16:9 or not – it seems maybe half stretched, like something midway between the two aspect ratios. It didn’t bother me. The output has very good contrast and color saturation. It’s also quite sharp, which isn’t necessarily a good thing. The 2001FP produces slightly fuzzier-looking output, which I think is more faithful to the appearance of an old-shool CRT, and helps make certain color-fringing artifacts less objectionable, but the difference is minor.
The AV2HDMI appears to have some kind of auto-configuring behavior, where it adjusts itself to the incoming video signal’s format, black levels, etc. This takes about two seconds, during which the image isn’t visible. Switching video modes on the Apple II (say between text and low-res graphics mode) forces a repeat of the auto-configure logic, so there’s a few seconds of black screen when switching modes. It’s a little bit annoying, but not too bad.
Testing
All of these tests but one were performed on an Apple IIgs. Pure text modes looked good in 40 and 80 columns, as did color games. The higher resolution GSOS desktop was acceptable in black and white, but suffered from minor shimmering and sparkle. GSOS in color was pretty bad, but remember this is still composite video, and GSOS never really looked very good on a composite monitor.
In the pure text modes, the computer disables the NTSC colorburst, which makes the monitor think it has a purely black and white video signal. This helps a lot, and results in a nice crisp image with the AV2HDMI. In low-res graphics mixed mode, with four lines of text at the bottom of the screen, the colorburst is enabled and the text looks markedly worse. Substantial amounts of green/purple fringing are visible on the edges of each text character. The 2001FP does a little bit better in this case, but still shows the same kinds of artifacts. I recall seeing those same green/purple artifacts back in the day, so I know they’re real and not due to some problem with the video conversion. I don’t recall them having been quite so dramatic as they appear now, but it’s been a long time.
AV2HDMI Photos

AV2HDMI color game
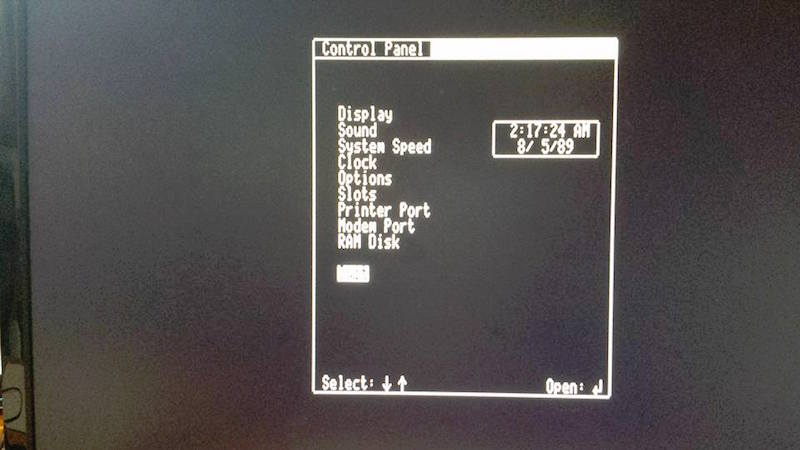
AV2HDMI pure text mode (80 column)
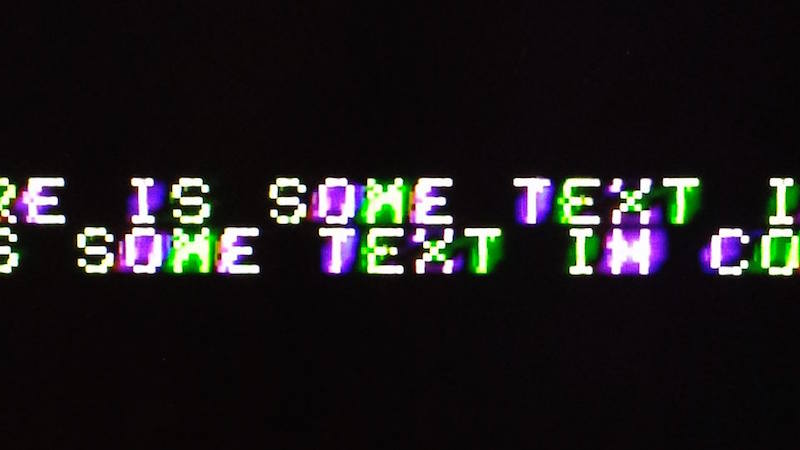
AV2HDMI mixed mode text close-up

AV2HDMI mixed mode text on Apple IIc
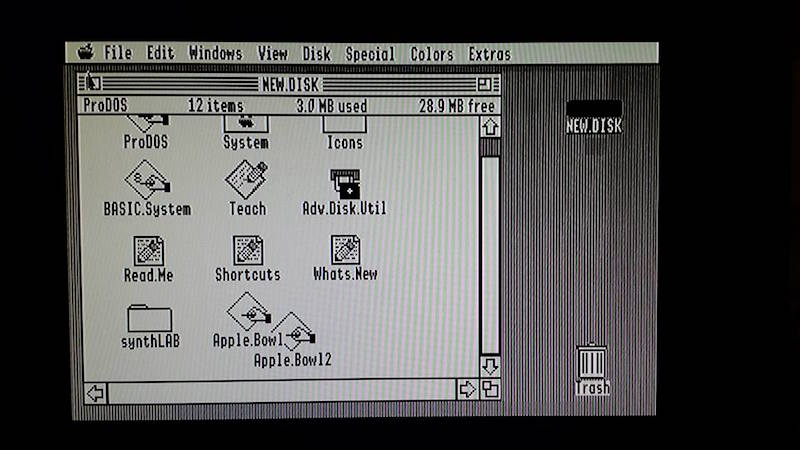
AV2HDMI GSOS desktop, monochrome mode
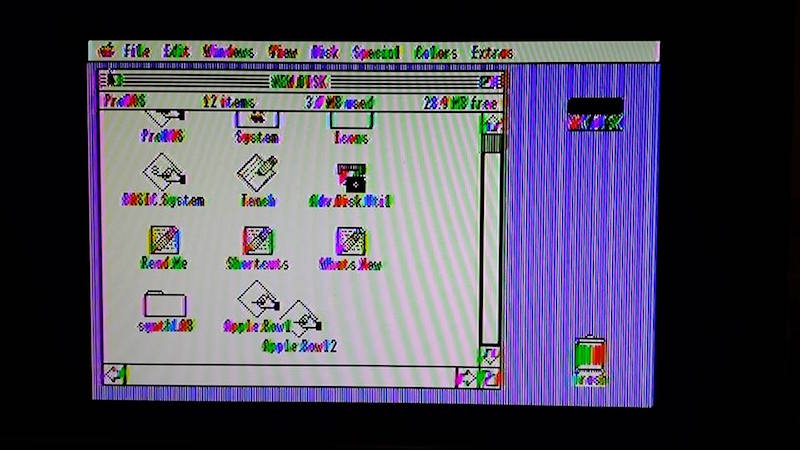
AV2HDMI GSOS desktop, color mode
Dell 2001FP Comparison Photos

2001FP color game
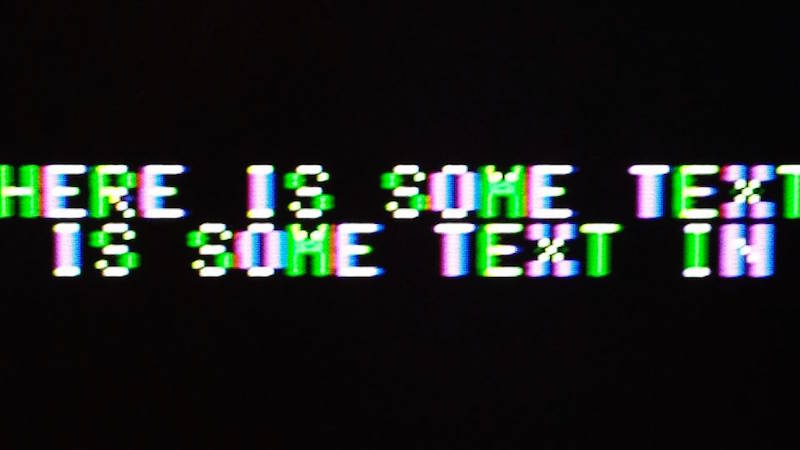
2001FP mixed mode text close-up
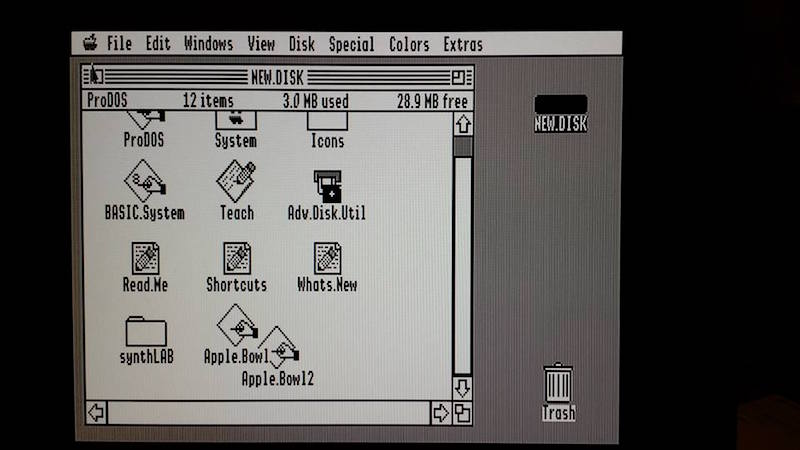
2001FP GSOS desktop, monochrome mode
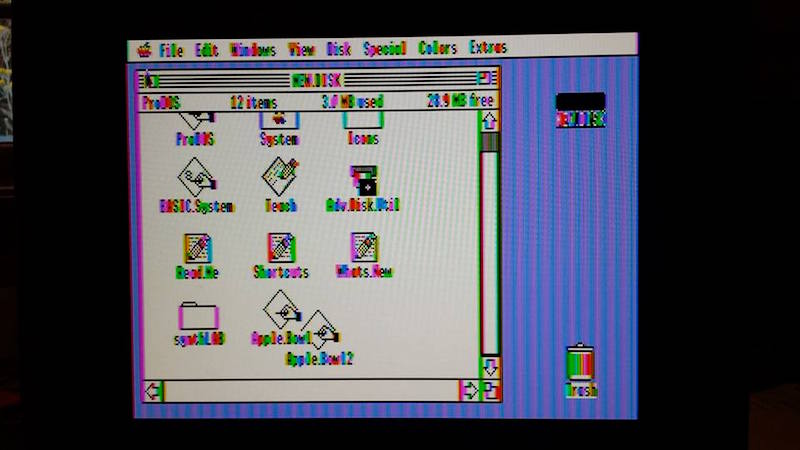
2001FP GSOS desktop, color mode
For the money, I think the AV2HDMI is a good solution for semi-frequent use. The Dell 2001FP was slightly better overall, and a real composite CRT would surely have been better still (I don’t have one). There are also machine-specific VGA adapters available for some Apple II systems. But because I don’t boot my Apple II hardware very often, this was exactly what I needed to simplify my set-up.
Read 7 comments and join the conversationThe Amiga Years

I recently watched a new documentary about the Amiga years: From Bedrooms to Billions. It’s a $5 Vimeo rental that will be fascinating for anyone who lived through the 1980’s home computer revolution, or who’s interested in retro-computing technology. I was pleased to see a fair amount of technical content, as well as tons of interviews and more general discussion of the Amiga “scene” and the contemporary computer industry. There’s some nice discussion of other period computer systems too, especially the Atari ST series.
Amiga was a Silicon Valley start-up company, founded by Jay Miner and staffed by many ex-Atari engineers. They ran into financial difficulties during development, and were eventually bought by Commodore. The first Commodore Amiga 1000 computer was released in 1985, and its graphics, sound, and multitasking capabilities were far beyond any other home computer of the time, except perhaps for the Atari ST. As a high school student, I bought a second-hand Amiga 1000 system in 1989 and was absolutely stunned by its graphics fidelity. Yet I never really got into programming or hacking with the Amiga, and in my life it functioned only as a fancy game machine. I switched to a Macintosh when I went to university, and never looked back.
The Amiga Years reminds me of a few other nice documentaries about early computer history.
Get Lamp – A two-hour look into text adventure games, their roots in spelunking and Dungeons and Dragons, and especially Colossal Cave Adventure and Infocom. You are likely to be eaten by a grue.
BBS: The Documentary – Before the internet was common for home users, there were modems and bulletin board systems. This documentary does a great job of describing the BBS scene, as well as some of the technical backstory surrounding protocols and software that I’d never heard before.
What tech documentaries have you seen and enjoyed?
Read 2 comments and join the conversationIntroducing the Mac ROM-inator II


Say hello to a new retro-computing gizmo – the Mac ROM-inator II! It will supercharge your vintage Macintosh II series or SE/30 computer, by replacing the stock ROM with a programmable flash memory module. Add a bootable ROM disk, change the startup sound, hack the icons, gain HD20 support and a 32-bit clean ROM. Go nuts! The Mac ROM-inator II is available now in the BMOW Store.
The flash ROM comes pre-programmed with a custom ROM image with the following changes as defaults:
- Customized startup chime – major 9th arpeggio
- ROM disk image provides a diskless booting option
- New startup menu screen displays installed RAM, addressing mode, and ROM disk details
- Built-in HD20 disk support
- 32-bit clean
- Memory test is disabled for faster booting
- Happy Mac icon is replaced by a color smiling “pirate” Mac
The ROM-inator II is derived from Doug Brown’s original Mac ROM SIMM design, used with permission. A portion of sales goes back to Doug.
ROM Hacking Magic
All the early Macintosh computers have some low-level functions stored in ROM. It’s the Mac equivalent of a PC’s BIOS. These ROM routines are responsible for initializing the computer when the power is first turned on, checking to see what hardware is installed, finding an attached disk with OS software on it, and booting that OS. Even after the OS has booted, the ROM routines still handle many low-level functions like interrupt handling, keyboard support, and floppy I/O, as well as some higher level functions like drawing windows and icons. If you can control the ROM, you can control virtually everything in the computer.
Nearly every member of the Macintosh II, Quadra, and LC families has a 64-pin ROM SIMM socket on the logic board. In some cases, the stock ROM is in this socket. In others, the stock ROM is soldered directly to the logic board, but it can be overridden by a ROM SIMM in the socket. All that’s necessary is to figure how to build a ROM SIMM that’s physically compatible, and then program it with appropriate software. A few years ago, the important details were reverse-engineered by Doug Brown and others at 68kmla.org in an epic forum thread that stretched to over 1000 posts.
The ROM-inator II is a standard PCB, shaped and sized to fit the ROM SIMM socket. It comes pre-programmed with a base ROM image that’s modeled off the Mac IIsi ROM. This is a universal ROM that’s also capable of working in many other members of the Mac II family, including the SE/30, Mac IIx, IIcx, IIci, and IIfx. By patching key ROM functions, it’s possible to alter the Mac’s behavior in fundamental ways – a new startup chime, support for additional disk types, and a modified Happy Mac being a few examples. All it takes is a 68K disassembler and a lot of patience.
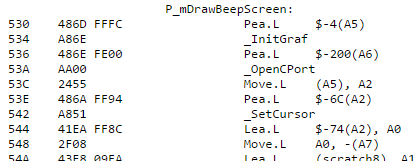
The stock ROM in most Macs of this period was around 512K in size, but the Mac’s address map devotes a full 8MB to ROM. In a normal Mac, the rest of this address space is unused. The ROM-inator II uses larger flash memory chips to take better advantage of the available address space. The first 512K of flash memory is used for the actual ROM code, and the rest is available for interesting goodies like a ROM disk image. Rob Braun’s original romdrv paved the way for ROM booting, and I’ve made several enhancements, including a startup menu and support for compressed disk images.
Compatibility
The pre-programmed ROM image is compatible with the Macintosh IIx, IIcx, IIci, IIfx, IIsi, and SE/30. The Mac ROM-inator II module is physically compatible with any Macintosh having a 64-pin ROM SIMM socket, except the Quadra 660AV and 880AV. This includes the previously mentioned models as well as many other Quadra, LC, and Performa models. For these other models, the flash memory will need to be reprogrammed with an appropriate ROM image.
For a similar ROM upgrade for the Macintosh Plus, 512Ke, 512K, and 128K, see the original Mac ROM-inator Kit.
HD20 Support and 32-Bit Clean ROM
A nice benefit of the pre-programmed ROM image is to add built-in support for HD20-type hard disks, such as the HD20 hard disk emulation mode of the BMOW Floppy Emu. The Macintosh IIx, IIcx, IIfx, and SE/30 lack HD20 support in their stock ROMs, so this replacement ROM enables those machines to use HD20 disks.
The pre-programmed ROM image also makes the Mac 32-bit clean, enabling it to use more than 8MB of RAM natively without the need for special system enablers or extensions. Some older Macintosh models like the IIx, IIcx, and SE/30 have stock ROMs that are “dirty”, meaning they can’t support 32-bit addressing without ROM patches. Using the Mac ROM-inator II and the pre-programmed ROM image, the Mac SE/30 can support up to 128MB of RAM!
ROM Disk
The built-in ROM disk is a 5.5MB bootable disk image containing System 7.1 and a collection of classic games. Using the ROM disk, it’s possible to create a diskless workstation without any physical disks attached. Once booted from the ROM disk, Appletalk file servers can also be mounted over a local network.
The ROM disk image is stored compressed in the module’s flash memory, and is decompressed on the fly as needed, in order to squeeze the largest possible disk image into the available space. This requires 1MB of RAM for caching of decompressed disk sectors, so a minimum of 2MB total system RAM is required. The ROM disk can be mounted as read-only, or as a read-write RAM disk.
Usage
When first powered on, the Macintosh will play a customized startup sound, and display diagnostic info about the amount of installed RAM, the current addressing mode, and the detected ROM disk type. After a moment, a startup menu will be displayed. To boot from the ROM disk as a read-only disk, press the R key on the keyboard. Or to convert the ROM disk into a writable RAM disk, press the A key. If no keys are pressed after five seconds, the Macintosh will boot normally from an attached SCSI disk, or wait for a floppy disk to be inserted.


Programming
The Mac ROM-inator II’s flash memory can be reprogrammed using an external SIMM programmer, providing the ultimate in customization. There’s 4MB of flash memory available for any purpose, like a custom ROM disk image, alternate ROM code, digitized sounds, user interface tweaks, or other crazy experiments. Using compression, this is enough for the base 512K ROM image plus a roughly 5.5MB uncompressed disk image. Or fill the whole space with a collection of different base ROMs, selected from a startup menu. Go crazy!
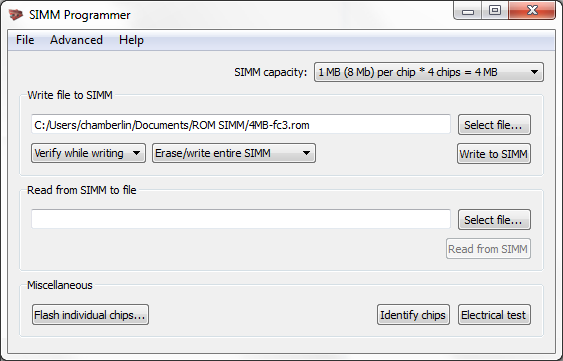
The SIMM programmer is currently a DIY project you can build yourself. See the schematics and PCB files, firmware, and host software on GitHub.
A second-generation SIMM programmer will be ready at the BMOW Store in summer 2016.
Happy ROM hacking!
Read 12 comments and join the conversationLower International Shipping Costs!

Good news for BMOW fans from outside the United States: international shipping costs for most orders should now be substantially lower than before. I wrote about the pain of international shipping costs a few weeks ago, and ever since then it’s been on my mind. Since about half of all BMOW customers are outside the US, I want to do everything I can to make their shopping easy and inexpensive, and I’m glad I’ve finally been able to address the shipping issue.
So how did I do it? The weight-based shipping rates haven’t changed, and those are set by the US Postal Service. Since I can’t lower the postage cost for a given weight, I instead focused on reducing the weight for a given item by using ultra-light packaging material whenever possible. Instead of shipping international orders in bulky and heavy cardboard boxes, many orders will now ship in padded mailing envelopes with a triple-layer of bubble wrap inside to protect the contents. I’ve tested this to several different destination countries, and it’s proven to protect the contents just as well as a box. Lower weight means lower shipping costs, so everybody wins.
International shipping costs for typical orders will be 40% cheaper thanks to this change. Most orders will now fall under the critical 0.5 pound threshold where higher postage rates take effect. Overseas customers will see typical shipping costs reduced from $24.25 to $15.25, and Canadian customers will see a reduction from $17.00 to $11.00. Hooray!
Read 2 comments and join the conversationFC8 – Faster 68K Decompression

Data compression is fun! I’ve written a new compression scheme that’s designed to be as fast as possible to decompress on a 68K CPU, while still maintaining a decent compression density. I’m calling it FC8, and you can get the generic C implementation and optimized 68K decompressor from the project’s Github repository. I’ve probably reinvented the wheel with this, and in a non-optimal way too, but once I started I found that I couldn’t stop. My intended platform for FC8 is 68020 and 68030-based vintage Macintosh computers, but it should be easily portable to other classic computers, microcontrollers, and similar minimal systems.
The main loop of the 68K decompressor is exactly 256 bytes, so it fits entirely within the instruction cache of the 68020/030. Decompression speed on a 68030 is about 25% as fast as an optimized memcpy of uncompressed data, which is essentially an unrolled loop of 4-byte move.l instructions with no computation involved. Compared to that, I think 25% is pretty good, but I can always hope for more. 🙂
In the previous post, I described how I was using compression to squeeze a larger rom-disk image into a custom replacement Macintosh ROM that I’m designing. I began with a compression algorithm called LZG, written by Marcus Geelnard. It worked well, but the 68K decompression seemed disappointingly slow. I tried to contact the author to discuss it, but couldn’t find any email address or other contact info, so I eventually drifted towards creating my own compression method loosely based on LZG. This became FC8. On a 68030 CPU, FC8 compresses data equally as tightly as LZG and decompresses 1.5x to 2x faster. FC8 retains much of the compression acceleration code from LZG, as well as the idea of quantizing lengths, but the encoding and decompressor are new.
The algorithm is based on the classic LZ77 compression scheme, with a 128K sliding history window and with duplicated data replaced by (distance,length) backref markers pointing to previous instances of the same data. No extra RAM is required during decompression, aside from the input and output buffers. The compressed data is a series of tokens in this format:
- LIT = 00aaaaaa = next aaaaaa+1 bytes are literals
- BR0 = 01baaaaa = backref to offset aaaaa, length b+3
- EOF = 01×00000 = end of file
- BR1 = 10bbbaaa’aaaaaaaa = backref to offset aaa’aaaaaaaa, length bbb+3
- BR2 = 11bbbbba’aaaaaaaa’aaaaaaaa = backref to offset a’aaaaaaaa’aaaaaaaa, length lookup_table[bbbbb]
The encoding may look slightly strange, such as only a single bit for the backref length in BR0, but this produced the best results in my testing with sample data. The length lookup table enables encoding of backrefs up to 256 bytes in length using only 5 bits, though some longer lengths can’t be encoded directly. These are encoded as two successive backrefs, each with a smaller length.
The biggest conceptual changes vs LZG were the introductions of the LIT and EOF tokens. EOF eliminates the need to check the input pointer after decoding each token to determine if decompression is complete, and speeds things up slightly. LIT enables a whole block of literals to be quickly copied to the output buffer, instead of checking each one to see if it’s a backref token. This speeds things up substantially, but also swells the size of the data. In the worst case, a single literal would encode as 1 byte in LZG but 2 bytes in FC8, making it twice as expensive! All the other changes were needed to cancel out the compression bloat introduced by the LIT token, with the end result that FC8 compresses equally as compactly as LZG. Both compressed my sample data to about 63% of original size.
The 68K decompressor code can be viewed here.
Decompression on the Fly
Several people mentioned the possibility of on-the-fly decompression, since the intended use is a compressed disk image. That’s something I plan to explore, but it’s not as simple as it might seem at first. Disk sectors are 512 bytes, but there’s no way to decompress a specific 512 byte range from the compressed data, since the whole compression scheme depends on having 128K of prior data to draw on for backref matches. You could compress the entire disk image as a series of separate 512 byte blocks, but then the compression density would go to hell. A better solution would compress the entire disk image as a series of larger blocks, maybe 128K or a little smaller, and then design a caching scheme to keep track of whether the block containing a particular sector were already decompressed and available. This would still have a negative impact on the compression density, and it would make disk I/O slower, but would probably still be OK.
Ultimately I think the two decompression approaches each have strengths and weaknesses, so the best choice depends on the requirements.
Boot-Time Decompression:
Pros: Best compression density, fastest I/O speeds once the disk image is decompressed
Cons: 5-10 second wait for decompression at boot time, requires enough RAM to hold the entire disk image
On-the-Fly Decompression:
Pros: No wait at boot time, required amount of RAM is configurable (size of the decompressed block cache)
Cons: Worse compression density, slower I/O speeds, more complex implementation
Hardware Tests
I discovered that a Macintosh IIci in 8-bit color mode decompresses about 20% slower than in 1-bit color mode. But a IIsi decompresses at the same speed regardless of the color settings. Both machines are using the built-in graphics hardware, which steals some memory cycles from the CPU in order to refresh the display. I’m not sure why only the IIci showed a dependence on the color depth. Both machines should be faster when using a discrete graphics card, though I didn’t test this.
The original LZG compression showed a much bigger speed difference between the IIci and IIsi, closer to a 50% difference, which I assumed was due to the 32K cache card in the IIci as well as its faster CPU. It’s not clear why the discrepancy is smaller with FC8, or whether it means the IIci has gotten worse or the IIsi has gotten better, relatively speaking. Compared to the same machine with the LZG compression, FC8 is 1.57x faster on the IIci and 1.99x faster on the IIsi. Based on tests under emulation with MESS, I was expecting a 1.78x speedup.
Tradeoffs
While working on this, I discovered many places where compression compactness could be traded for decompression speed. My first attempt at FC8 had a minimum match size of 2 bytes instead of 3, which compressed about 0.7% smaller but was 13% slower to decompress due to the larger number of backrefs. At the other extreme, the introduction of a LIT token without any other changes resulted in the fastest decompression speed of all, about 7% faster than FC8, but the compressed files were about 6% larger, and I decided the tradeoff wasn’t worth it.
I explored many other ideas to improve the compression density, but everything I thought of proved to have only a tiny benefit at best, not enough to justify the impact on decompression speed. An algorithm based on something other than LZ77 would likely have compressed substantially more densely, or say a combination of LZ77 and Huffman coding. But decompression of LZ77-based methods are far easier and faster to implement.
Compression Heuristics
It eventually became obvious to me that defining the token format doesn’t tell you much about how to best encode the data in that format. A greedy algorithm seemed to work fairly well, so that’s what I used. At each point in the uncompressed data, the compressor substitutes the best match it can make (if any) between that data and previous data in the history window.
However, there are some examples where choosing a non-optimal match would allow for an even better match later, resulting in better overall compression. This can happen due to quirks in the quantizing of match lengths, or with long runs of repeated bytes which are only partially matched in the previous data. It’s a bit like sacrificing your queen in chess, and sometimes you need to accept a short-term penalty in order to realize a long-term benefit. Better compression heuristics that took this into account could probably squeeze another 1% out of the data, without changing the compression format or the decompressor at all.
Read 11 comments and join the conversation