

Archive for the 'Bit Bucket' Category
The Story of Tetris Max
It was the summer of 1992. Nirvana smelled like teen spirit, Ross Perot was running for president, and I was a senior at the Massachusetts Institute of Technology who wanted to play tetris. Looking at the options then available for my Macintosh LC computer, none of them were inspiring. My friends were all addicted to a beautifully crafted Mac falling blocks game called Jewelbox, and I wondered if I could make a Macintosh tetris with the same level of polish. And so began the story of Tetris Max, a game that was to play a major role in my life for the next decade.
I had only a shaky understanding of the C language, and a weak grasp of Mac programming fundamentals. This was before the days when any programming question could be answered in seconds at stackoverflow.com, so knowledge had to be gained the hard way, reading through the five thick printed volumes of Inside Macintosh. Somehow I cobbled together a working game.
Before long, I had dozens of friends camped out in my room day and night, competing for high scores and offering feedback on dropping speed, rotation rules, key repeat behavior, and other fine points that made the difference between a so-so game and a great one. We polished the hell out of that thing, arguing over arcane details until the gameplay was dialed perfectly. Then I agonized over all the little graphics elements and sound effects, for events like dropping a piece, advancing to the next level, or getting a high score. Somehow a mooing cow found its way in there too. I became obsessed with perfecting every aspect of the game until it was buttery smooth.
For music, I chose the instrumental portion of Jesus Jones’ song Blissed. It had that ethereal quality appropriate for trance-like extended play at level 10. Over lunch one day, a few friends and I argued over what meaningless suffix would be best for the game title. Tetris Gold? Tetris Pro? Tetris Plus? How about Tetris Max? Yes, that’s it!
At the time there were dozens of tetris versions available, including the popular xtetris, and Asshole Tetris, which cheated against the player. I was aware that the game concept originated with a Russian man, but it seemed a generic idea like chess or tennis, and it didn’t occur to me that I shouldn’t call it “tetris”. This came back to haunt me later.
Launch
In August 1992, I uploaded the first version of Tetris Max to the Info-Mac archive and America Online, which was about as advanced as Mac software distribution got at the time. I prayed that somebody would notice my submission, and… surprise! Somebody did. A lot of somebodies! I started receiving an extraordinary number of emails from all over the world, from people telling me how much they enjoyed playing Tetris Max. It was beyond the best I’d hoped for. The game was a hit!
Everyone wanted to know about their high score. How did it compare to others? What was the highest score ever achieved? People shared their stories of deep states of meditation achieved on level 10, the final level where human reflexes were just barely fast enough to keep up, where marathon length tetris sessions were possible, but where a single mistake was fatal. Others claimed the game helped them get to sleep each night, or reduced their stress levels, like a form of therapy. As for myself, I played the game so much that I began to see falling shapes in my mind whenever I closed my eyes, and would mentally rotate and drop them without any conscious thought.



By that winter Tetris Max had become a major force in the world of Macintosh games, and the excitement level continued to grow. I was invited to appear in a book about Macintosh shareware called Mac Arcade: Don Rittner’s Top Shareware Game Picks. The book included several pages about Tetris Max, including a rather silly biography of me. When I later saw it on sale at a local bookstore, it was one of the most exciting things to yet happen in my young life. And it helped ratchet up the level of Tetris Max mania even further.
After the game had been out for a few months, I was contacted by Peter Wagner, an amateur musician and tetris fan from New Jersey. He loved Tetris Max, and offered to compose some original music for it. The song he sent me was perfect for tetris: beautiful, memorable, and almost meditative without becoming annoying when it was looped 1000 times. When I released an update to Tetris Max, I substituted in Peter’s music, and it became the iconic Tetris Max music that anyone who’s ever played the game probably still remembers today. A funny bit of trivia: Peter sent me his song on a cassette tape, which I digitized using a tape deck whose motor was too slow. So the music in the game is transposed down about a whole step from Peter’s original composition.


Through 1993, the Tetris Max train continued gathering steam. The October 1993 issue of MacUser magazine (feature article: the new Apple Newton) gave it an honorable mention in their annual shareware awards. My name was in print again, and unlike the Mac Arcade book, it was spelled right! Exciting times for a young Macintosh fan.
Making It Pay
By mid 1993 I had graduated from M.I.T. and was living in Cambridge, Massachusetts. This whole time Tetris Max had been a free game, and the only thing I asked people for was a note saying hi. Most other Macintosh games at the time were distributed as shareware, a try-before-you-buy system in which people were asked to send money to the author if they liked the program. With the popularity of Tetris Max, I heard loud arguments from my friends that I was an idiot for not using the shareware idea myself, so I decided to give it a try. In September 1993 I released a new version of the game as a $10 shareware product.
The response was weak at first. Players were under the honor system to send the shareware fee, but there was nothing really motivating them except perhaps a guilty conscience. Later I implemented a nag screen, and an A.I. player feature that was unlocked only for registered customers, both of which helped boost the number of registrations somewhat. But the total remained low.
What really made a difference was the introduction of the “Bonus Disk Set” in 1994. Recognizing that most people needed some incentive to register shareware, I gave them one in the form of a collection of alternate tetris piece graphics, sounds, and music to use with the game. Because only registered users were eligible to purchase the bonus disk set, it spurred lots of new registrations.
In those days there was no PayPal or other easy way to send small amounts of money to a stranger, so the registration system was incredibly low-tech. I rented a box at the Cambridge post office in Central Square, a few blocks from where I lived. Customers wrote paper checks and mailed them to my P.O. box. I used a cheesy XOR algorithm to generate a registration code from their name, then mailed them back a letter with the code. It was tremendously labor-intensive, and I spent hours manually typing people’s names into a database and stuffing envelopes. But low-tech or not, the system worked, and for a while I earned a very nice side income from shareware registration fees. Steve Wozniak even registered the game on behalf of his kids charity. His check was signed just “Woz”.
Receiving payments from people outside the United States was a big problem. My bank would generally not accept checks drawn on non-US banks, or if they did, the service fee was greater than the amount of the check. Other solutions like international money orders didn’t work well either. Eventually I settled on a simple solution: cash. Plain old pound notes, francs, deutschmarks, and reals, plucked from a wallet and stuffed in an envelope. I could convert these to US cash for a small fee at any bank or money changer, but in practice I kept many of them as souvenirs. Sending cash through the mail sounds like it might be a risky idea due to possible mail theft, but I never had even a single cash registration go missing.
Over time, several alternate versions of Tetris Max were developed. In 1994 my friend Yev ported the game to Windows 3.1 and released it as Bricklayer. We split the shareware income between us, but it was never very much, as Bricklayer for Windows never enjoyed anywhere near the popularity of Tetris Max for Macintosh. I also reused much of the same code to develop Columns Max in 1995, and Dr. Max in 1997. Neither game was very successful, and to be honest Columns Max was pretty bad, but I’m proud of Dr. Max. It has a great feel and cute little animations, and is lots of fun to play.

The most important alternate version appeared in the Mac Arcade Pak, published by MacSoft. Beginning in 1994, the game appeared (as Bricklayer) in this collection of five Macintosh games sold across the country at stores like Comp USA and Micro Center. It was low-cost budget software, and I only earned a 25 cent royalty for each one, but MacSoft sold a tremendous number of that Arcade Pak. My relationship with MacSoft’s partner Varcon Systems grew in importance as the Mac Arcade Pak took off. Once when I was buying a new monitor at Comp USA, the woman ahead of me in the checkout line was buying the Mac Arcade Pak. But when I casually mentioned that I’d written one of the games, she didn’t seem impressed. 🙂
By 1996 things were going well, and my Cambridge P.O. box was stuffed with envelopes whenever I visited. But I had a problem: I was moving to California. I could release a new version with a new address for registrations, but so many copies of the old version remained in circulation that the Cambridge box was sure to keep receiving letters for a long time to come. My solution was to hire my grad student friend Tom to check the Cambridge box for me, and forward the letters to my new address in California. Problem solved… for a while at least.
Even as the Macintosh platform lost market share, the popularity of the game was undiminished. I continued to get emails and letters from enthusiastic players around the world, and everyone still wanted to know about their high score. I finally got fed up with manual registration processing in 1997. Opening envelopes, database entry, post office runs, bounced checks… it was all too much, so I contracted with Kagi Shareware to process the registrations for me. Letters went directly to Kagi, who handled all the money, registration codes, and customer correspondence. They took a big chunk of the income in exchange for their service, but it was worth it for all the headache that it saved me.
The End of Things
In 1998 I received a letter from New York law firm LeBoeuf, Lamb, Greene & MacRae LLP on behalf of The Tetris Company, an organization with the sole purpose of licensing the tetris brand. The letter claimed that both Tetris Max and Columns Max infringed on the trademark, copyright, and other rights of The Tetris Company, and demanded that I immediately stop all distribution and sales of the games. Though I didn’t know it at the time, this was part of a broad effort by TTC in the late 90’s to remove all freeware and shareware versions of tetris from the market.

Some aspects of these claims seemed dubious to me, as it’s subjective to what extent the “look and feel” of a software program is protected by copyright, and Columns Max was not a tetris game at all. But the “tetris” trademark infringement was more clear, and it seemed I was straight-up wrong in using that as part of the game’s name. After briefly consulting with a lawyer, who wasn’t much help, I decided I didn’t have the resources or the desire to fight. I removed Tetris Max from the internet wherever I could, instructed Kagi to stop accepting shareware registrations, and formally terminated my contract with Varcon.
But stopping Tetris Max proved easier said than done. Because there were so many copies of the game still in circulation, registrations continued to arrive at Kagi and at my old P.O. box. I had to send letters back to all those would-be-registrants, returning their checks. Kagi complained that they were spending hours doing the same thing for the registrations that reached them, yet not getting paid for their efforts, but there was nothing I could do about it. It took about two years for the tide of incoming registrations to finally taper off.
As an interesting post-script, in 2000 I became involved in another legal dispute over Tetris Max, after the game had already been discontinued for more than 18 months. Varcon received a summons to Massachusetts civil court, for a suit related to Tetris Max and the Mac Arcade Pak. It was part of a complex dispute involving derivatives of
Tetris, Missile Command, Pac Man, Dig Dug, and Asteroids. In all there were 4 or 5 companies suing, including Elorg and Hasbro, and 10 different companies being sued. There was no question of trademark infringement this time, and the entire case rested on claims of look and feel copyright violations.
Two months later, I saw a press release saying that Varcon had settled their part of the case, although it mentioned Pac Man and not Tetris. I never heard anything further about the case.
The two companies, GT Interactive and Varcon Systems, agreed to stop selling look-alike games of titles owned or licensed by Hasbro. GT Interactive and Varcon, for example, sold games like “Mac-Man” and “Munch Man,” which Hasbro said infringed on its copyright of “Pac-Man.”
Hasbro said it would continue to pursue its suit against eGames. and smaller companies Webfoot, MVP Software and Xtreme Games.
Some people may read this story and conclude I’m a bad person for unfairly using somebody else’s idea, and to a large extent I would agree. In hindsight it would certainly have been better if I’d developed a new game concept instead of recycling an existing one. Like many projects gone awry, it seemed like a good idea at the time.
It’s now 2015, and the Macintosh operating system looks radically different than it did in the 90’s. Tetris Max can’t even run on today’s Macs, outside of an emulator for vintage software. Yet two decades later, I still get occasional emails from fans, and they STILL want to know about their high scores. Some things never change!
Read 17 comments and join the conversationBackups: Head in the Sand

For two decades, I’ve head my head in the sand when it comes to the topic of backups. My strategy has been:
- Put lots of essential, irreplaceable work-related design files on PC
- Every 2-3 years, copy some files to an external hard disk, if I feel like it
- Put the external disk away in a closet, then forget where it is
Somehow I’ve escaped any major disasters due to accidental file deletion, disk failures, theft, or fire. It took some recent news stories about the CryptoWall 4.0 ransomware to finally motivate me to action. If you’re not familiar with CryptoWall, this thing is nasty. It encrypts everything on your PC, including external drives and mapped networked drives, such as those you might use to store backups. The only recourse is to restore from offsite backups that CryptoWall didn’t hit, or pay the ransom to unlock your data. While the current version of CryptoWall only affects Windows systems, the same techniques could appear on Macs and Linux desktop or server systems.
Like most of you, my household contains piles of computing devices of various types. There’s a Windows PC, two Mac laptops, a Mac Mini (used for media streaming), a Chromebook, and several assorted tablets and smartphones. Then there’s the BMOW web site to consider, as well as another web site I also administer. Below I describe the backup solution I chose for each device, the cost, and possible alternatives.
Chromebook, Media Streaming Computer, Tablets, Phones
Backup Solution: None
Cost: 0
Some devices store little or no data locally, and don’t really need to be backed up. I might lose some photos if the hardware were destroyed, but that’s about all. I’m comfortable with none of this being backed up.
Mac Laptops
Backup Solution: Time Machine
Cost: 0*
I elected to use Apple’s built-in backup software, Time Machine. It’s blissfully simple to set up and use, and it runs automatically once it’s configured. It maintains as many older versions of your files as it can fit on your backup disk, removing older versions once the backup disk becomes full.
My cost for the Time Machine setup was zero, because I already had the necessary hardware on hand. My router has a USB port where a disk can be attached, turning it into a network-accessable drive. And I just happened to have a moderate-sized USB disk sitting unused, which fit the requirements perfectly. Otherwise I might have paid $50 to $200 for a suitable disk and something to attach it to.
The main drawback of this Time Machine setup is that it relies on networked attached storage, located at the same premises as the computers themselves. While there’s currently no Mac version of CryptoWall or anything similar, someday there might be, and it’s likely it would hit the Time Machine backups too on the networked disk. And if my house burns down, the backups will be lost along with the Macs. Both of those worries could be addressed by backing up the backups to cloud storage, but I’m not going there just yet for these machines.
Windows PC
Backup Solution: External Disk and CrashPlan Cloud Backup
Cost: $61 + $60/year
The Windows PC contains the data I’d be most upset to lose. That includes all of my electronics and software projects, including the design files and firmware for Floppy Emu and the BMOW 1 Computer. That PC also holds thousands of personal photos and videos going back 15 years, and plenty of other irreplaceable data.
To safeguard this data, I’ve chosen a hybrid setup that includes both a local disk and cloud backup. The hardware’s been purchased, but nothing is yet configured – that’s on my to-do list for this week. The local disk is there because it’s fast and cheap: $61 for a 1.5 terabyte USB 3.0 drive. If I ever need to do a complete restore, it should only take hours, compared to the days or weeks it might require to restore hundreds of gigabytes of data from a cloud service. CrashPlan‘s cloud backup is there as a second line of defense, in case something like CryptoWall also hits the backup drive, or theft or fire destroy everything local. Maybe I’m overly paranoid, but I’m more comfortable with that extra level of protection on the Windows PC.
CrashPlan costs $60/year for one computer, with unlimited backup space. I specifically chose it over other options because it’s one of the few cloud backup services that will also do local backups through the same interface that’s used to manage cloud backups. Configuring two separate backup systems for local and cloud backups would be a pain.
To be honest, I don’t love this solution. All of the cloud backup services have a sort of seedy used car salesman feel about them. If you believe the reviews, customer service is often horrible, and you’re constantly confronted by upsell efforts to a more expensive service tier.
Since I’m not about to physically rotate backup disks to a bank vault somewhere, the main alternative is other cloud storage services that aren’t specifically marketed as backup solutions. For small backups, something like Dropbox or Google Drive might be enough. For more typically sized backups, especially for ones storing many past file versions instead of only a single snapshot, something like Amazon S3 storage makes more sense. But what tools would I use to transfer the backups to S3 in a completely automated way, and how much would it cost?
S3’s “infrequent access” storage is just 1.25 cents per gigabyte per month, (plus 1 cent per gigabyte when retrieving data, something that should rarely or never happen for backups). That makes it cheaper than CrashPlan for up to 400 GB of backup storage, and more expensive beyond 400 GB. My Windows PC backups, including all past versions of files, will probably be a few hundred GB, so from a price standpoint it’s a toss-up. But considering the ease of using CrashPlan’s service vs backing up to S3, CrashPlan is the clear winner. If I had multiple PCs needing backup to the cloud, or other special requirements, then S3 backup storage might make more sense.
BMOW and Other Web Sites
Backup Solution: UpdraftPlus Backup/Restore and Dreamhost DreamObjects
Cost: $70 + $4/year
I expected backing up my web sites to be easy: shouldn’t the hosting provider already take care of this? As it turns out, mine does, but not in a way that’s really acceptable. There are three automated backup snapshots, with imprecise times of 1-2 hours, 1-2 days, and 1-2 weeks. The site’s files and database are also backed up independently, with no guarantee that the separate file and data backups will be from the same moment in time. While this backup system might be enough to recover from a disaster, it could easily be insufficient, especially if a restore is needed that’s older than two weeks.
I was a little surprised to learn that there aren’t any simple backup solutions for web servers, similar to the options available for workstation PCs and Macs. The closest thing is a backup plugin for WordPress, one of the most popular web publishing packages, and the one I use for my sites. I chose the feature-rich UpdraftPlus Backup/Restore, which is the most popular of the WordPress backup plugins. It seems to work well enough, but something about a backup solution that’s implemented as a WordPress plugin just feels wrong:
- Not every server hosts a web site
- Not every web site runs WordPress
- A WordPress backup plugin makes special assumptions about the files and data it’s backing up
- Most WordPress backup plugins only backup the WP files and data, and ignore other files/data
It was that last bullet point that bit me. On both of the web sites that I maintain, there are large numbers of important files located outside the WordPress directory, in the site’s main root directory. One of the sites also has a second database that’s completely independent of the WordPress database. The free versions of the more popular WordPress backup plugins can’t handle these, which would leave me with an incomplete backup. I ended up paying $70 for the premium version of UpdraftPlus, solely for its ability to also backup non-WordPress files and databases. While I don’t mind paying money for good software, this didn’t seem like the cost matched the complexity of the feature I needed, and only confirmed my feeling that a WordPress plugin isn’t a great framework for a backup tool.
Just as with backing up a desktop machine, the server backup files need to be stored somewhere else. While in theory I could store the backups on the server itself, that wouldn’t protect against a disaster that nuked the whole server, and it’s also a violation of my web host’s “unlimited” hosting policy. I chose to store the web site backups to DreamObjects, a cloud storage service that directly competes with Amazon’s S3 and uses the same API. I chose DreamObjects because it’s provided by the same company that does my hosting, so there was nothing extra to sign up for. UpdraftPlus has built-in support for storing backups with DreamObjects, and the integration was easy. As it turned out, DreamObjects will be slightly more expensive than S3 for my level of data storage. But since the total cost will be about $4/year, I’m not going to lose sleep over a few pennies.
The main alternative to a WordPress plugin backup system is a shell script, executed regularly as a cron job on the server. I probably should have investigated that further, but I invented my own cloud of FUD to convince myself it wasn’t worth it. It might not be too difficult to run tar and mysqldump, and transfer the resulting backups to DreamObjects, but building a more robust backup system would take time. A good system would also need to prune old backups, handle errors gracefully, chunk large uploads, generate reports, and address encryption needs. Maybe I’ve overestimated the level of work it would require, but it sounds like just the sort of dull but important stuff that I would neglect.
Your Backup Story
What’s been your experience with backup systems? Has your head been in the sand, like mine? Instead of finishing with a backup horror story, I’ll leave this success story from Slashdot here instead:
I support a medium business. Cryptowall 2.0 found its way onto a key system and spread through mapped drives to the fileserver. The panic was epic. Boss near tears.
I nuked the compromised systems and restored from backups. No big deal. The unenlightened around me had pretty much given up hope and I was hailed as a hero the next day.
Got a fat bonus and some OT.
10/10 would restore from backups again.
Four Little Updates
Some brief updates on Floppy Emu, Plus Too, and the DiskCopy2Dsk tool:
Two Apple IIc Plus testers reported this week that the Floppy Emu disk emulator is incompatible in 3.5 inch emulation mode with that machine. If you’re not familiar with the IIc+, it’s an uncommon member of the Apple II family, and is a souped-up version of the more common IIc with an internal 3.5 inch floppy drive. While 5.25 inch disk emulation and Smartport hard disk emulation work fine with the IIc+, 3.5 inch emulation does not, for unknown reasons. Apparently the disk interface on the IIc+ differs from that on the IIgs and on the external Apple 3.5 Drive, which were the basis for Floppy Emu’s 3.5 inch Apple II emulation mode. Unfortunately IIc+ systems are fairly rare, and I don’t have one to test. If anyone has technical info on the IIc+ disk interface that they could share, please contact me.
A minor update of the Floppy Emu firmware for Lisa and Mac HD20 is available: hd20-0.7C-F14.5. This resolves an issue where a “fatal error: 0x96 sync” sometimes occurred during file copies in HD20 mode. Thanks to Joe Strosnider for reporting this issue and helping to text the fix. You can download the new firmware from the Floppy Emu page.
For anyone working with Macintosh DiskCopy 4.2 disk images, a bug was fixed in the command-line version of the dc2dsk tool. The tool converts DiskCopy 4.2 disk images into raw .dsk images with no header. Now that Floppy Emu directly supports DC42 image files, the tool isn’t necessary anymore, but if anyone’s used it for other purposes this will fix a bug in the image size calculation. For the curious, more info about why this tool was needed can be found here.
Magnus Karlsson has ported the Plus Too design to the Pipistrello FPGA board. Plus Too is a working hardware replica of the Macintosh Plus computer, originally developed by me in 2011. Recently Till Harbaum revived the project, ported it to the MiST FPGA board, and made major fixes and improvements. Magnus picked up the MiST code and adapted it to the Pipistrello board, where it’s still a work in progress but successfully boots to the Mac desktop. More info on this project is in the Saanmila discussion forum.
Be the first to comment!A Handmade Executable File
Make a Windows program by stuffing bytes into a buffer and writing it to disk: no compiler, no assembler, no linker, no nothing! It was the obvious conclusion of my recent efforts to gain more control over what goes into my executables, and this time I could set every bit exactly as I wanted it. Yes, I am still a control freak.
I began with a simple C program called ExeBuilder to construct the buffer and write it to disk in a file named handmade.exe. ExeBuilder looks like this:
#include "stdafx.h"
#include <Windows.h>
int main(int argc, char* argv[])
{
HANDLE hFile = CreateFile("handmade.exe", GENERIC_WRITE, 0, NULL, CREATE_ALWAYS,
FILE_ATTRIBUTE_NORMAL, NULL);
BYTE* buf = (BYTE*) HeapAlloc(GetProcessHeap(), HEAP_ZERO_MEMORY, 1024);
DWORD exeSize = BuildExe(buf);
DWORD numberOfBytesWritten;
WriteFile(hFile, buf, exeSize, &numberOfBytesWritten, NULL);
HeapFree(GetProcessHeap(), 0, buf);
CloseHandle(hFile);
printf("wrote handmade.exe\n");
return 0;
}
All of the interesting work happens in BuildExe(). This function manually constructs a valid Windows PE header, filling the required header fields and leaving the optional ones zeroed, then creates a single .text section and fills it with a few bytes of program code. The program in this case doesn’t do much – it just returns the number 44.
Sorting out the PE header details and determining which fields were actually required was a chore. All my testing was performed under Windows 7 64-bit edition. If you try these examples on your PC, it appears that earlier versions of Windows were more permissive with PE headers, while Windows 8 and 10 may be more strict about empty PE fields.
Here’s my first implementation of BuildExe(), which makes a nice standard executable with a single .text section containing 4 bytes of code.
inline void setbyte(BYTE* pBuf, DWORD off, BYTE val) { pBuf[off] = val; }
inline void setword(BYTE* pBuf, DWORD off, WORD val) { *(WORD*)(&pBuf[off]) = val; }
inline void setdword(BYTE* pBuf, DWORD off, DWORD val) { *(DWORD*)(&pBuf[off]) = val; }
inline void setstring(BYTE* pBuf, DWORD off, char* val) { lstrcpy((char*)&pBuf[off], val); }
DWORD BuildExe(BYTE* exe)
{
// 1. DOS HEADER, 64 bytes
setstring(exe, 0, "MZ"); // DOS header signature is 'MZ'
setdword(exe, 60, 64); // DOS e_lfanew field gives the file offset to the PE header
// 2. PE HEADER, at offset DOS.e_lfanew, 24 bytes
setstring(exe, 64, "PE"); // PE header signature is 'PE\0\0'
setword(exe, 68, 0x14C); // PE.Machine = IMAGE_FILE_MACHINE_I386
setword(exe, 70, 1); // PE.NumberOfSections = 1
setword(exe, 84, 208); // PE.SizeOfOptionalHeader = offset between the optional header and the section table
setword(exe, 86, 0x103); // PE.Characteristics = IMAGE_FILE_32BIT_MACHINE | IMAGE_FILE_EXECUTABLE_IMAGE | IMAGE_FILE_RELOCS_STRIPPED
// 3. OPTIONAL HEADER, follows PE header, 96 bytes
setword(exe, 88, 0x10B); // Optional header signature is 10B
setdword(exe, 104, 4096); // Opt.AddressOfEntryPoint = RVA where code execution should begin
setdword(exe, 116, 0x400000); // Opt.ImageBase = base address at which to load the program, 0x400000 is standard
setdword(exe, 120, 4096); // Opt.SectionAlignment = alignment of section in memory at run-time, 4096 is standard
setdword(exe, 124, 512); // Opt.FileAlignment = alignment of sections in file, 512 is standard
setword(exe, 136, 4); // Opt.MajorSubsystemVersion = minimum OS version required to run this program
setdword(exe, 144, 4096*2); // Opt.SizeOfImage = total run-time memory size of all sections and headers
setdword(exe, 148, 512); // Opt.SizeOfHeaders = total file size of header info before the first section
setword(exe, 156, 3); // Opt.Subsystem = IMAGE_SUBSYSTEM_WINDOWS_CUI, command-line program
setdword(exe, 180, 14); // Opt.NumberOfRvaAndSizes = number of data directories following
// 4. DATA DIRECTORIES, follows optional header, 8 bytes per directory
// offset and size for each directory is zero
// 5. SECTION TABLE, follows data directories, 40 bytes
setstring(exe, 296, ".text"); // name of 1st section
setdword(exe, 304, 4); // sectHdr.VirtualSize = size of the section in memory at run-time
setdword(exe, 308, 4096); // sectHdr.VirtualAddress = RVA for the section
setdword(exe, 312, 4); // sectHdr.SizeOfRawData = size of the section data in the file
setdword(exe, 316, 512); // sectHdr.PointerToRawData = file offset of this section's data
setdword(exe, 332, 0x60000020); // sectHdr.Characteristics = IMAGE_SCN_MEM_READ | IMAGE_SCN_MEM_EXECUTE | IMAGE_SCN_CNT_CODE
// 6. .TEXT SECTION, at sectHdr.PointerToRawData (aligned to Opt.FileAlignment)
setbyte(exe, 512, 0x6A); // PUSH
setbyte(exe, 513, 0x2C); // value to push
setbyte(exe, 514, 0x58); // POP EAX
setbyte(exe, 515, 0xC3); // RETN
return 516; // size of exe
}
The resulting file is 516 bytes. Check to make sure it works:
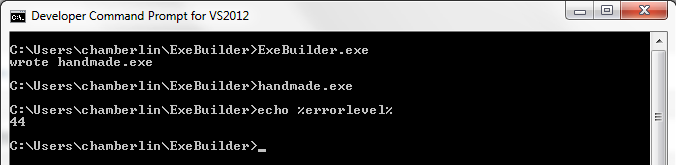
The executable is built from six data structures, which are numbered in the code’s comments. The cross-references in these structures are sometimes specified as offsets within the file, and sometimes as relative virtual addresses or RVAs. File offsets reflect the executable as it exists on disk, while RVAs reflect how it’s loaded in memory at run-time. An RVA is a run-time offset from the executable’s base address in memory. Getting these two confused will lead to problems!
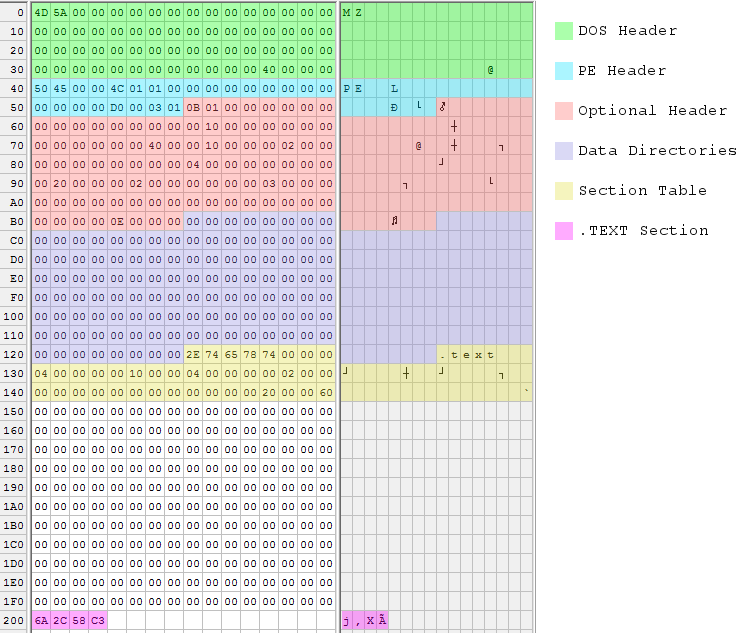
DOS Header – The only fields that must be filled are the ‘MZ’ signature at the beginning and the e_lfanew parameter at the end (unless you’re actually writing a DOS program). e_lfanew gives the offset to the PE header, which in this case follows immediately after.
PE Header – The true PE header doesn’t contain much, because all the good stuff is in the optional header. The PE header specifies 1 section (the single .text section with the code to return 44), and 208 bytes combined size for the next two sections.
Optional Header – The optional header is only optional if you don’t care whether the program works. Some noteworthy values:
- SectionAlignment – Each section of the executable (.text, .data, etc) must be alignment to this boundary in memory at run-time. The standard is 4096 or 4K, the size of a single page of virtual memory.
- AddressOfEntryPoint – Program execution will begin at this memory offset from the base address. Because the section alignment is 4096, the program’s single .text section will be loaded at offset 4096, and execution should begin at the first byte of that section.
- FileAlignment – Similar to section alignment, but for the file on disk instead of the program in memory. The standard is 512 bytes, the size of a single disk sector.
- SizeOfHeaders – This isn’t really the combined size of all the headers, but rather the file offset to the first section’s data. Normally that’s the same as the combined size of all headers plus any necessary padding.
Data Directories – A typical executable would store offsets and sizes for its data directories here, the number of which is given in the optional header. Data directories are used to specify the program’s imports and exports, references to debug symbols, and other useful things. Manually constructing an import data directory is a bit complicated, so I didn’t do it. That’s why the program just returns 44 instead of doing something more interesting that would have required Win32 DLL imports. Handmade.exe does not have any data directories at all.
If you’re wondering why there are 14 data directories each with zero offset and size, instead of just specifying zero data directories, that’s a small mystery. According to tutorials I read, some parts of the OS will attempt to find info in data directories even if the number of data directories is zero. So the only safe way to have an empty data directory is to have a full table of offsets and sizes, all set to zero. However, I found other examples that did specify zero data directories and that reportedly worked fine. I didn’t look into the question any further, since it turned out not to matter anyway.
Section Table – For each section, there’s an entry here in the section table. Handmade.exe only has a single .text section, so there’s just one table entry. It gives the section size as 4 bytes, which is all that’s needed for the “return 44” code. The section will be loaded in memory at RVA 4096, which is also the program’s entry point.
Section Data – Finally comes the actual data of the .text section, which is x86 machine code. This is the meat of the program. The section data must be aligned to 512 bytes, so there’s some padding between the section table and start of the section data.
Here’s what dumpbin says about this handmade executable. Many of the fields are zero or have bogus values, but it doesn’t seem to matter:
Microsoft (R) COFF/PE Dumper Version 11.00.50727.1
Copyright (C) Microsoft Corporation. All rights reserved.
Dump of file handmade.exe
PE signature found
File Type: EXECUTABLE IMAGE
FILE HEADER VALUES
14C machine (x86)
1 number of sections
0 time date stamp Wed Dec 31 16:00:00 1969
0 file pointer to symbol table
0 number of symbols
D0 size of optional header
103 characteristics
Relocations stripped
Executable
32 bit word machine
OPTIONAL HEADER VALUES
10B magic # (PE32)
0.00 linker version
0 size of code
0 size of initialized data
0 size of uninitialized data
1000 entry point (00401000)
0 base of code
0 base of data
400000 image base (00400000 to 00401FFF)
1000 section alignment
200 file alignment
0.00 operating system version
0.00 image version
4.00 subsystem version
0 Win32 version
2000 size of image
200 size of headers
0 checksum
3 subsystem (Windows CUI)
0 DLL characteristics
0 size of stack reserve
0 size of stack commit
0 size of heap reserve
0 size of heap commit
0 loader flags
E number of directories
0 [ 0] RVA [size] of Export Directory
0 [ 0] RVA [size] of Import Directory
0 [ 0] RVA [size] of Resource Directory
0 [ 0] RVA [size] of Exception Directory
0 [ 0] RVA [size] of Certificates Directory
0 [ 0] RVA [size] of Base Relocation Directory
0 [ 0] RVA [size] of Debug Directory
0 [ 0] RVA [size] of Architecture Directory
0 [ 0] RVA [size] of Global Pointer Directory
0 [ 0] RVA [size] of Thread Storage Directory
0 [ 0] RVA [size] of Load Configuration Directory
0 [ 0] RVA [size] of Bound Import Directory
0 [ 0] RVA [size] of Import Address Table Directory
0 [ 0] RVA [size] of Delay Import Directory
SECTION HEADER #1
.text name
4 virtual size
1000 virtual address (00401000 to 00401003)
4 size of raw data
200 file pointer to raw data (00000200 to 00000203)
0 file pointer to relocation table
0 file pointer to line numbers
0 number of relocations
0 number of line numbers
60000020 flags
Code
Execute Read
Summary
1000 .text
Sometimes a picture is worth 1000 words, so I also made a color-coded hex dump of the executable file:
Shrinking It
After doing all this, of course my first thought was to try making it smaller. There’s a lot of empty padding between the section table and the section data, due to the 512 byte alignment of sections in the file. There must be some way to shrink or eliminate that padding, right? I tried reducing Opt.FileAlignment to 4, moving the .TEXT section data down to 336, and adjusting sectHdr.PointerToRawData accordingly. All I got for my effort was an error complaining “handmade.exe is not a valid Win32 application.” I’m unsure why it didn’t work. Maybe the OS doesn’t like sections that aren’t 512 byte aligned in the file, no matter what the PE header says.
Then I thought maybe I could reuse the header as the section data. By changing sectHdr.PointerToRawData to 0, I could make the Windows loader use a copy of the executable header as the .TEXT section data. 0 is 512 byte aligned, so there wouldn’t be any alignment problems. It seemed strange, since an executable header is not x86 code, but by stuffing the 4 bytes of code into an unused area of the header and adjusting Opt.AddressOfEntryPoint, I could theoretically patch everything up. Lo and behold, it worked! The new executable was only 340 bytes.
With the 4 bytes of code now stored inside the header, I wondered if I really needed a section at all. The Windows loader will load the header into memory along with all the sections, so maybe I could just eliminate the .TEXT section completely, and rely on the entry point address to point the way to the code stored in the header?
This worked too, but not without a lot of futzing around. After setting PE.NumberOfSections to 0, PE.SizeOfOptionalHeader and Opt.SizeOfHeaders both had to be set to zero. They’re both essentially offsets to section structures, and with no sections, apparently a 0 offset is required. Opt.SectionAlignment also had to be reduced to 2048, and I honestly have no idea why. With those changes, the modified program worked.
With the elimination of the section table, this should have been enough to shrink the executable to 300 bytes, but I found that anything smaller than 328 bytes wouldn’t work. It appeared that the OS assumes a minimum size for the optional header or the data directories, regardless of the sizes specified in the header. So 28 bytes of padding are required at the end of handmade.exe. The 328 byte version of BuildExe() is shown here, with the changes from the previous version highlighted:
DWORD BuildExe(BYTE* exe)
{
// 1. DOS HEADER, 64 bytes
setstring(exe, 0, "MZ"); // DOS header signature is 'MZ'
setdword(exe, 60, 64); // DOS e_lfanew field gives the file offset to the PE header
// 2. PE HEADER, at offset DOS.e_lfanew, 24 bytes
setstring(exe, 64, "PE"); // PE header signature is 'PE\0\0'
setword(exe, 68, 0x14C); // PE.Machine = IMAGE_FILE_MACHINE_I386
setword(exe, 70, 0); // PE.NumberOfSections = 1
setword(exe, 84, 0); // PE.SizeOfOptionalHeader = offset between the optional header and the section table
setword(exe, 86, 0x103); // PE.Characteristics = IMAGE_FILE_32BIT_MACHINE | IMAGE_FILE_EXECUTABLE_IMAGE | IMAGE_FILE_RELOCS_STRIPPED
// 3. OPTIONAL HEADER, follows PE header, 96 bytes
setword(exe, 88, 0x10B); // Optional header signature is 10B
setdword(exe, 104, 296); // Opt.AddressOfEntryPoint = RVA where code execution should begin
setdword(exe, 116, 0x400000); // Opt.ImageBase = base address at which to load the program, 0x400000 is standard
setdword(exe, 120, 2048); // Opt.SectionAlignment = alignment of section in memory at run-time, 4096 is standard
setdword(exe, 124, 512); // Opt.FileAlignment = alignment of sections in file, 512 is standard
setword(exe, 136, 4); // Opt.MajorSubsystemVersion = minimum OS version required to run this program
setdword(exe, 144, 4096*2); // Opt.SizeOfImage = total run-time memory size of all sections and headers
setdword(exe, 148, 0); // Opt.SizeOfHeaders = total file size of header info before the first section
setword(exe, 156, 3); // Opt.Subsystem = IMAGE_SUBSYSTEM_WINDOWS_CUI, command-line program
setdword(exe, 180, 14); // Opt.NumberOfRvaAndSizes = number of data directories following
// 4. DATA DIRECTORIES, follows optional header, 8 bytes per directory
// offset and size for each directory is zero
// 5. SECTION TABLE, follows data directories, 40 bytes
// no section table
// 6. .TEXT SECTION, at sectHdr.PointerToRawData (aligned to Opt.FileAlignment)
setbyte(exe, 296, 0x6A); // PUSH
setbyte(exe, 297, 0x2C); // value to push
setbyte(exe, 298, 0x58); // POP EAX
setbyte(exe, 299, 0xC3); // RETN
return 328; // size of exe
}
Here’s another pretty picture, showing the 328 byte executable file:
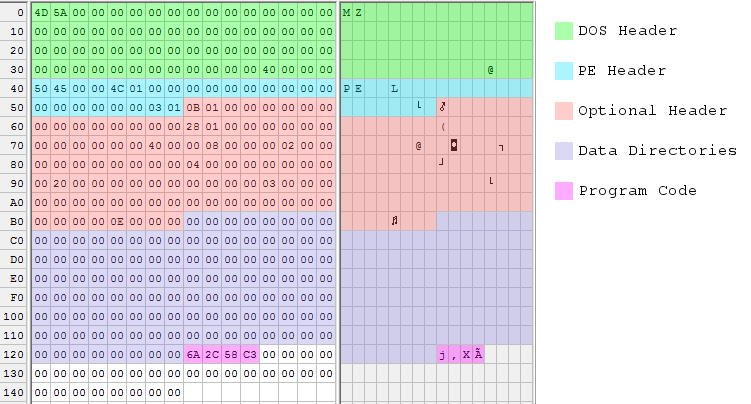
Maximum Shrinking
328 bytes was pretty good, but of course I wanted to do better. A popular technique seen in other “small PE” examples is to move down the PE header and everything that follows it, so that it overlaps the DOS header. This is possible because most of the DOS header is just wasted space, as far as a Windows executable is concerned.
The PE header can be moved down as low as offset 4 within the file. It must be 4-byte aligned, and it can’t be at offset 0 because then it would overwrite the required ‘MZ’ signature at the start of the file. Doing this is simple: just move everything but the DOS header down by 60 bytes.
The only complication with overlapping the DOS and PE headers this way is with the DWORD at file offset 60. This value is the e_lfanew parameter that gives the file offset to the PE header, so it now must be 4. But due to the overlapping, it’s also the Opt.SectionAlignment parameter that specifies the alignment between sections in memory at run-time. Hopefully Windows is OK with a 4-byte section alignment! It turns out that it’s fine, but only if Opt.FileAlignment is also 4. I’m not sure why.
These changes should have been enough to shrink the file to 240 bytes, but once again the OS seems to require 28 bytes of padding at the end of the file. Here’s the updated 268 byte version of BuildExe():
DWORD BuildExe(BYTE* exe)
{
// 1. DOS HEADER, 64 bytes
setstring(exe, 0, "MZ"); // DOS header signature is 'MZ'
// don't set DOS.e_lfanew, it's part of the overlapped PE header
// 2. PE HEADER, at offset DOS.e_lfanew, 24 bytes
setstring(exe, 64-60, "PE"); // PE header signature is 'PE\0\0'
setword(exe, 68-60, 0x14C); // PE.Machine = IMAGE_FILE_MACHINE_I386
setword(exe, 70-60, 0); // PE.NumberOfSections = 1
setword(exe, 84-60, 0); // PE.SizeOfOptionalHeader = offset between the optional header and the section table
setword(exe, 86-60, 0x103); // PE.Characteristics = IMAGE_FILE_32BIT_MACHINE | IMAGE_FILE_EXECUTABLE_IMAGE | IMAGE_FILE_RELOCS_STRIPPED
// 3. OPTIONAL HEADER, follows PE header, 96 bytes
setword(exe, 88-60, 0x10B); // Optional header signature is 10B
setdword(exe, 104-60, 296-60); // Opt.AddressOfEntryPoint = RVA where code execution should begin
setdword(exe, 116-60, 0x400000); // Opt.ImageBase = base address at which to load the program, 0x400000 is standard
setdword(exe, 120-60, 4); // Opt.SectionAlignment = alignment of section in memory at run-time, 4096 is standard
setdword(exe, 124-60, 4); // Opt.FileAlignment = alignment of sections in file, 512 is standard
setword(exe, 136-60, 4); // Opt.MajorSubsystemVersion = minimum OS version required to run this program
setdword(exe, 144-60, 4096*2); // Opt.SizeOfImage = total run-time memory size of all sections and headers
setdword(exe, 148-60, 0); // Opt.SizeOfHeaders = total file size of header info before the first section
setword(exe, 156-60, 3); // Opt.Subsystem = IMAGE_SUBSYSTEM_WINDOWS_CUI, command-line program
setdword(exe, 180-60, 14); // Opt.NumberOfRvaAndSizes = number of data directories following
// 4. DATA DIRECTORIES, follows optional header, 8 bytes per directory
// offset and size for each directory is zero
// 5. SECTION TABLE, follows data directories, 40 bytes
// no section table
// 6. .TEXT SECTION, at sectHdr.PointerToRawData (aligned to Opt.FileAlignment)
setbyte(exe, 296-60, 0x6A); // PUSH
setbyte(exe, 297-60, 0x2C); // value to push
setbyte(exe, 298-60, 0x58); // POP EAX
setbyte(exe, 299-60, 0xC3); // RETN
return 268; // size of exe
}
And another pretty picture, with some color blending going on where data structures overlap:
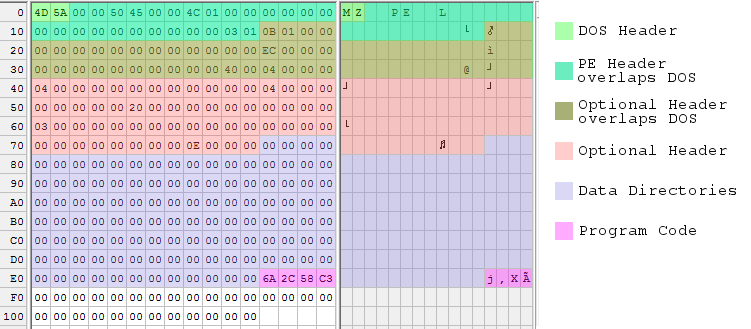
According to several sources, 268 bytes is the absolute minimum size for a working executable under Windows 7 64-bit edition. There are other tricks that would shrink the header even more, but then I’d just have to add more padding. I can go no further!
Read 15 comments and join the conversationAssembly Language Windows Programming
Who says assembly language programming is dead? Keeping with my recent theme of peering inside Windows executable files, I decided to bypass C++ completely and try writing a Windows program entirely in assembly language. I was happy to discover that it’s not difficult, especially if you have a bit of prior assembly experience for any CPU. My first example ASM program is only 17 lines! Granted it doesn’t do very much, but it demonstrates a skeleton that can be extended to create exactly the program I want – no more futzing around with C compiler options to prevent mystery “features” from being added to my code. Yes, I am a control freak.
1. Minimal Assembly Example
Here’s a simple example:
.686 .model flat, stdcall EXTERN MessageBoxA@16 : proc EXTERN ExitProcess@4 : proc .const msgText db 'Windows assembly language lives!', 0 msgCaption db 'Hello World', 0 .code Main: push 0 push offset msgCaption push offset msgText push 0 call MessageBoxA@16 push eax call ExitProcess@4 End Main
If you’ve got any version of Microsoft Visual Studio installed on your PC, including the free Visual Studio Express versions, then you’ve already got MASM: the Microsoft Macro Assembler. Save the example file as msgbox.asm, and use MASM to build it from the command line like this:
> ml /coff /c /Cp msgbox.asm > link /subsystem:windows /out:msgbox.exe kernel32.lib user32.lib msgbox.obj
That doesn’t look too complicated. Let’s examine it line by line.
.686
This tells the assembler to generate x86 code that’s compatible with the Intel 686 CPU or later, aka the Pentium Pro. Any Intel-based machine from the past 15-20 years will be able to run this, so it’s a good generic default. You can also use .386, .486, or .586 here if you want to avoid generating any instructions not compatible with those older CPUs.
.model flat, stdcall
The memory model for all Win32 programs is always flat. The second parameter gives the default calling convention for procedures exported from this file, and can be either C or stdcall. Nothing is exported in this example, so the choice doesn’t really matter, but I’ll choose stdcall.
When one function calls another, it must somehow pass the arguments to the called function. The caller and callee must agree on where the arguments will be placed, and in what order, or else the code won’t work correctly. If the arguments are passed on the stack, then the two functions must also agree on who’s responsible for popping them off afterwards, so the stack can be restored to its original state. These details are known as the calling convention.
All of the Win32 API functions use the __stdcall convention, while C functions and the C library use the __cdecl (or just plain “C”) convention. You may also rarely see the __fastcall convention; look it up for more details. stdcall and cdecl conventions are similar: both pass arguments on the stack, and the arguments are pushed in right to left order. So a function whose prototype looks like:
MyFuction(arg1, arg2, arg3)
is called by pushing arg3 onto the stack first, followed by arg2 and arg1:
push arg3 push arg2 push arg1 call MyFunction
These two conventions only differ regarding stack cleanup. With cdecl, the calling function is responsible for removing arguments from the stack, whereas with stdcall it’s the called function’s responsibility to do stack cleanup before it returns.
EXTERN MessageBoxA@16 : proc
EXTERN ExitProcess@4 : proc
These lines tell MASM that the code makes reference to two externally-defined procedures. When the code is assembled into an .obj file, references to these procedures will be left pending. When the .obj file is later linked to create the finished executable, it must be linked with other .obj files or libraries that provide the definitions for these external references. If definitions aren’t found, you’ll see the familiar linker error message complaining of an “unresolved external symbol”.
The funny @4 and @16 at the end of the function names is the standard method of name mangling for stdcall functions, including all Win32 functions. A suffix is added to the name of the function, with the @ symbol and the total number of bytes of arguments expected by the function. This mangled name is the symbol that appears in the .obj file or library, and not the original name. The actual symbol name is also prefixed with an underscore, e.g. _MessageBox@16, but MASM handles this automatically by prefixing an underscore to all statically imported or exported public symbols.
To find the number of bytes of arguments expected by a Win32 stdcall function, you can view the online MSDN reference and add up the argument sizes manually, or you can use something like dumpbin /symbols user32.lib to view the mangled names of functions in an import library.
For cdecl functions, there’s no name mangling. The name of the symbol is just the name of the function prefixed with an underscore, e.g. _strlen.
Most of the time you don’t see this level of detail, because the compiler or assembler knows the calling convention and argument list of any functions you call, so it can do name mangling automatically behind the scenes. But in this example, I never told MASM what the calling convention is for MessageBox or ExitProcess, nor the number and sizes of the arguments they expect, so it can’t help with name mangling and I have to provide the mangled names manually. In a minute, I’ll show a nicer way to handle this with MASM.
.const
The .const directive indicates that whatever follows is constant read-only data, and should be placed in a separate section of the executable called .rdata. The memory for this section will have the read-only attribute enforced by the Windows virtual memory manager, so buggy code can’t modify it by mistake. Other possible data-related section directives are .data for read-write data, and .data? for uninitialized read-write data.
msgText db ‘Windows assembly language lives!’, 0
msgCaption db ‘Hello World’, 0
The next lines allocate and initialize storage for two pieces of data named msgText and msgCaption. Because the previous line was the .const directive, this data will be placed in the executable’s .rdata section. db is the assembler directive for “define byte”, and is followed by a list of comma separated byte values. The values can be numeric constants, string literals, or a mix of both as shown here. The 0 after each string literal is the null terminator byte for C-style strings.
.code
.code indicates the start of a new section, and whatever follows is program code rather than data. It will be placed in a section of the executable called .text. Why doesn’t the directive match the section name?
Main:
Here the code defines a label called Main, which can then be used as a target for jump instructions or other instructions that reference memory. Main refers to the address at which the next line of code is assembled. There’s nothing magic about the word “Main” here, and label names can be anything you want as long as they’re not MASM keywords.
push 0
push offset msgCaption
push offset msgText
push 0
This code pushes the arguments for MessageBox onto the stack, in right to left order as required by the stdcall convention. According to MSDN, the prototype of MessageBox is:
int WINAPI MessageBox(HWND hWnd, LPCTSTR lpText, LPCTSTR lpCaption, UINT uType);
The first argument pushed onto the stack is the value for uType, a 4-byte unsigned integer. The value 0 here corresponds to the constant MB_OK, and means the MessageBox should contain a single push button labeled “OK”. Next the addresses of the caption and text string constants are pushed. The offset keyword tells MASM to push the memory address of the strings, and not the strings themselves, and is similar to the & operator in C. Finally the hWnd argument is pushed, which is a handle to the owner of the message box. The value 0 used here means the message box has no owner.
call MessageBoxA@16
Now the Win32 MessageBox function is finally called. call will push the return address onto the stack, and then jump to the address of _MessageBoxA@16. It will use the arguments previously pushed onto the stack, display a message box, and wait for the user to click the OK button before returning. Because it’s a stdcall function, MessageBox will also remove the arguments from the stack before returning to the caller. The return value from calling MessageBox will be placed in the EAX register, which is the standard convention for Win32 functions.
Notice that the code specifically called MessageBoxA, with an A suffix that indicates the caption and text are single-byte ASCII strings. The alternative is MessageBoxW, which expects wide or double-byte Unicode strings. Many Win32 functions exist with both -A and -W variants like this.
push eax
call ExitProcess@4
The return value from MessageBox is pushed onto the stack, and ExitProcess is called. Its prototype looks like:
VOID ExitProcess(UINT uExitCode);
It takes a single argument for the program’s exit code. In this example, whatever value is returned by MessageBox will be used as the exit code. This is the end of the program – the call to ExitProcess never returns, because the program is terminated.
End Main
The end statement closes the last segment and marks the end of the source code. It must be at the end of every file. The optional address following end specifies the program’s entry point, where execution will begin after the program is loaded into memory. Alternatively, the entry point can be specified on the command line during the link step, using the /entry option.
ml /coff /c /Cp msgbox.asm
link /subsystem:windows /out:msgbox.exe kernel32.lib user32.lib msgbox.obj
ml is the name of the MASM assembler. Running it will create the msgbox.obj file.
/coff instructs MASM to create an object file in COFF format, compatible with recent Microsoft C compilers, so you can combine assembly and C objects into a single program.
/c tells MASM to perform only the assembly step, stopping after creation of the .obj file, rather than also attempting to do linking.
/Cp tells MASM to preserve the capitalization case of all identifiers.
link is the Microsoft linker, the same one that’s invoked behind the scenes when building C or C++ programs from Visual Studio.
/subsystem:windows means this is a Windows GUI-based program. Change this to /subsystem:console for a text-based program running in a console window.
/out:msgbox.exe is the name to give the executable file that will be generated.
The remainder of the line specifies the libraries and object files to be linked. MessageBox is implemented in user32 and ExitProcess in kernel32, so I’ve included those libraries. I didn’t provide the path to the libraries, so the linker will search the directories specified in the LIBPATH environment variable. The Visual Studio installer normally creates a shortcut in the start menu to help with this: it’s called “Developer Command Prompt for Visual Studio”, and it opens a console window with the LIBPATH and PATH environment variables set appropriately for wherever the development tools are installed.
2. Improvements with MASM Macros and MASM32
MASM is a “macro assembler”, and contains many macros that can make assembly programming much more convenient. For starters, I could define some constants to replace the magic zeroes in the arguments to MessageBox:
MB_OK equ 0h MB_OKCANCEL equ 1h MB_ABORTRETRYIGNORE equ 2h MB_YESNOCANCEL equ 3h MB_YESNO equ 4h MB_RETRYCANCEL equ 5h NULL equ 0
In the preceding example, I had to do manual name mangling of Win32 function names, and push the arguments onto the stack one at a time. This can be avoided by using the MASM directives PROTO and INVOKE. Much like a function prototype in C, PROTO tells MASM what calling convention a function uses, and the number and types of the arguments it expects. The function can then be called in a single line using INVOKE, which will verify that the arguments are correct, perform any necessary name mangling, and generate push instructions to place the arguments on the stack in the proper order. Using these directives, the lines related to MessageBoxA in the example program could be condensed like this:
MessageBoxA proto stdcall :DWORD,:DWORD,:DWORD,:DWORD
invoke MessageBoxA, NULL, offset msgText, offset msgCaption, MB_OK
Many people using MASM will use it in combination with MASM32, which provides a convenient set of include files containing prototypes for common Windows functions and constants. This enables the relevant lines of the MessageBox example to be further simplified to:
include \masm32\include\windows.inc
include \masm32\include\user32.inc
invoke MessageBoxA, NULL, offset msgText, offset msgCaption, MB_OK
Take a look at Iczelion’s excellent tutorial for a MessageBox example program making good use of all the MASM and MASM32 convenience features.
3. Structured Programming with MASM
The biggest headache writing any kind of non-trivial assembly language program is that all the little details quickly become tedious. A simple if/else construct must be written as a CMP instruction combined with a few conditional and unconditional jumps around the separate clauses. Allocating and using local variables on the stack is a pain. Working with objects and structures requires calculating the offset of each field from the base of the structure. It’s a giant hassle.
Nothing can relieve all the tedium (this is assembly language after all), but MASM is a big help. Directives like .IF, .ELSE, and .LOCAL make it possible to write assembly code that almost looks like C. Instructions are automatically generated to reserve and free space for stack-based locals, and the locals can be referenced by name instead of with awkward constructs like EBP-8. MASM also supports the declaration of C-style structs with named and typed fields. The result can be assembly code that’s surprisingly readable. Borrowing snippets from another Iczelion tutorial:
; structure definition from windows.inc
WNDCLASSEXA STRUCT
cbSize DWORD ?
style DWORD ?
lpfnWndProc DWORD ?
cbClsExtra DWORD ?
; ... more fields
WNDCLASSEXA ENDS
WinMain proc hInst:HINSTANCE, hPrevInst:HINSTANCE, CmdLine:LPSTR, CmdShow:DWORD
LOCAL wc:WNDCLASSEX
LOCAL msg:MSG
mov wc.cbSize, SIZEOF WNDCLASSEX
mov wc.style, CS_HREDRAW or CS_VREDRAW
mov wc.lpfnWndProc, OFFSET WndProc
mov wc.cbClsExtra, NULL
; ... more code
invoke RegisterClassEx, addr wc
; ... more code
.WHILE TRUE
invoke GetMessage, ADDR msg, NULL, 0, 0
.BREAK .IF (!eax)
invoke TranslateMessage, ADDR msg
invoke DispatchMessage, ADDR msg
.ENDW
mov eax, msg.wParam
ret
WinMain endp
This almost reads like C, and you might wonder how different it really is from writing C code. Despite the appearance, it’s still 100 percent assembly language, and the instructions in the .asm file are exactly what will appear in the final executable. There’s no optimization happening, no instruction reordering, and no true code generation in any complex sense. Directives like LOCAL that hide individual assembly instructions are just complex macros.
If I find enough motivation, I’ll write another post soon that shows a more full-featured assembly language program using these techniques. Now if you want to know WHY in the 21st century someone would write Windows programs in assembly language, I don’t have a great answer. It might be useful if you need to do something extremely specific or performance critical. But if you’re like me, the only reason needed is that fact that it’s there, underlying everything that’s normally done with higher level languages. Whenever I see a black box like that, I want to open the lid and peek inside.
Read 7 comments and join the conversationWhat Happens Before main()
Did you know that a C program’s main() function is not the first code to be run? Depending on the program and the compiler, there are all kinds of interesting and complex functions that get run before main(), automatically inserted by the compiler and invisible to casual observers. For the past several days I’ve been on a quest to reverse engineer a minimal C program, to see what’s inside the executable file and how it’s put together. I was generally aware that some kind of special initialization happened before main() was called, but knew nothing about the details. As it turned out, understanding what happens before main() proved to be central to explaining large chunks of mystery code that I’d struggled with during my first analysis.
In my previous post, I used dumpbin, OllyDbg, and the IDA disassembler to examine the contents of a Windows executable file created from an 18 line C program. This example program is a text console application that only references printf, scanf, and strlen. The C functions compile into 120 bytes of x86 code. Yet dumpbin revealed that the executable file contained 2234 bytes of code, and imported 38 different functions from DLLs. It also located over 1300 bytes of unknown data and constants. The implementations of printf etc were in a C runtime library DLL, so that couldn’t explain the unexpected code bloat. Something else was at work.
Scaffold for a C Program
By compiling with debug symbols, loading the executable in a debugger, and examining the disassembly, I was able to see the true structure of the example program. This included all the things happening behind the scenes. You can view the complete disassembly with symbols here. Here’s an outline, based on compiling with Microsoft Visual Studio Express 2012, for a release build with compiler settings selected to eliminate all extras like C++ exception handling and array bounds checking. Pseudocode function names are my descriptions and don’t necessarily match the names obtained from debug symbols.
ProgramEntryPoint()
{
security_init_cookie();
// beginning of __tmainCRTStartup()
setup_SEH_frame();
// call init functions from a table of function pointers:
// from pre_c_init()
is_managed_app = ParseAppHeader(); // checks for initial "MZ" bytes, PE header fields
init_exit_callbacks();
run_time_error_checking_initialize(); // calls init functions from an empty table
matherr();
setusermatherr(matherr);
setdefaultprecision(); // calls controlfp_s(0) and maybe calls invoke_watson()
configthreadlocale(); // for C library function string formatting of numbers and time
CxxSetUnhandledExceptionFilter(myExceptionFilter);
// from pre_cpp_init()
register_exit_callback(run_time_error_checking_terminate);
get_command_line_args();
// check tls_init_callback
if (dynamic_thread_local_storage_callback != 0 && IsNonWritableInCurrentImage())
{
dynamic_thread_local_storage_callback();
}
// now the C program runs
retVal = main();
// C program has now finished
if (!is_managed_app)
{
// clean-up C library, and terminate process
exit(retVal);
}
else
{
// clean-up C library, but do not terminate process
cexit();
cleanup_SEH_frame();
return retVal;
}
}
IsNonWritableInCurrentImage()
{
check_security_cookie();
return (ValidateImageBase() &&
IsNonWritable(FindPESection()));
}
myExceptionFilter()
{
if (IsRecognizedExceptionType())
{
terminate();
break_in_debugger();
}
}
register_exit_callback(pCallback)
{
setup_SEH_frame();
onexit(pCallback);
// also maintains onexit callbacks for DLLs
cleanup_SEH_frame();
}
This was enough to help me identify the general purpose of most of the code in the executable file, even if the details weren’t all entirely clear. During the program analysis in my previous post, I was confused by large chunks of code that didn’t appear to be called from anywhere. The answer to that mystery was tables of function pointers, which I discovered are used in many places during program startup to call a whole series of initialization functions. The addresses of the functions are stored in a table in the data section, and then the address of the table is passed to _initterm. I’d thought _initterm had something to do with terminal settings, but it’s actually just a helper function to iterate over a table and call each function.
Even with that mystery explained, there were still quite a few snippets of unreachable code in the disassembly. Most of these were only 5 or 10 lines of code, and appeared to be related to other nearby functions. My guess is that many of these scaffold/startup functions were written in assembly language by Microsoft developers, and the linker can’t tell which lines are actually used or not. As a result of some conditionally-included features, or just carelessness on the part of the compiler development team, a few lines of orphaned code were left over and got included into my example program’s executable.
Exploring the Scaffold Functions
Let’s start at the entry point and work our way through the scaffold functions.
security_init_cookie is related to a compiler-generated security feature that checks for buffer overruns. This function generates a cookie value based on the current time and other data that’s difficult for an attacker to predict. On entry to an overrun-protected function, the cookie is put on the stack, and on exit, the value on the stack is compared with the global cookie. In this example program, buffer overrun checking was explicitly disabled in the compiler settings, yet security_init_cookie is called anyway. Hmm.
Next the structured exception handling frame is configured on the stack. SEH is a Windows mechanism that’s used to catch and handle CPU exceptions. I’ve never used them, but I believe they can be used to handle errors like division by zero or invalid memory references.
The next set of functions are called from a pointer table that’s placed in the data section, rather than by direct function calls. The code parses the in-memory executable header, including the DOS and PE headers, to determine whether this is a managed app or if it’s native code. It then initializes the exit callbacks, a mechanism that can be used to register other functions to be called when the program exits. Following this, it calls a function to initialize run-time error checks, another compiler-generated feature that can catch problems with type conversions and uninitialized variables. In the example program, run-time error checks were disabled in the compiler settings. The call to init RTC is still present, but it uses an empty table of function pointers to do its work, and so it ultimately does nothing.
After this it calls the math error handler, and then installs that error handler. I’m not sure why it directly calls the math error handler first, but it’s a stub function that does nothing and returns zero.
The call after the math handler initialization is to an internal function called setdefaultprecision, which sets the precision used for floating point calculations. The implementation of this function is curious. It calls controlfp_s(0) to set the precision, and if this returns an error, it invokes the Doctor Watson debugger. This is the only place in any of the scaffolding code where Doctor Watson is referenced or used. If it’s used at all, I would have expected to see it as part of the exception handling mechanism, but in fact it’s only called here during initialization of the floating point precision.
The last task performed by pre_c_init is to configure the locale settings, to help make correctly-formatted numbers and date strings in the C standard library functions.
Next, the scaffold code registers a handler to be used for SEH exceptions. This handler is mostly useless. If the exception is one of four recognized types, the handler calls terminate and then performs an INT 3 debugger break. Otherwise it just returns without doing anything.
After that, the code registers an exit callback function which terminates the run-time error checking feature. The registration mechanism makes use of SEH frames. It also appears to handle exit functions for DLLs, although I was unclear about exactly how that works. I assume that if a DLL used by the program needs to perform some kind of clean-up code or destructors before the program exits, it can register a callback here.
get_command_line_args does what it sounds like, and initializes argc, argv, and envp. I never really thought about it before, but of course these need to be provided by the operating system somehow, and this is where it happens.
The next piece of code is the most complicated and confusing of the whole lot. The code checks the value of something called __dyn_tls_init_callback, which is a global variable initialized to zero in the program’s .data section. This appears related to thread local storage – an area of memory that’s unique for each thread. If __dyn_tls_init_callback is not zero (though I don’t see any mechanism that could make it be non-zero), it calls another internal function called IsNonWritableInCurrentImage. This is the beginning of a fairly involved group of functions that scan the in-memory DOS and PE headers, and attempt to locate a particular section in the PE header. Depending on what it finds there, it may or may not call the __dyn_tls_init_callback function. Notably, IsNonWritableInCurrentImage also makes use of the security cookie for detecting buffer overruns.
Finally, after all this setup work, at last it’s time to call the C main() function. Hooray! This is where the real work happens, and what most people think of as “the program” when they talk about a C-based software application.
Eventually the C program finishes its work, and control returns from main(). The scaffolding code is now responsible for cleaning things up and shutting everything down in an orderly manner. If it was previously determined that this is not a managed app, the code simply calls exit() to terminate the process. On the other hand, if it is a managed app, the scaffold code calls cexit(), cleans up the SEH frame, and returns control to whomever originally called the entry point.
Efficiency
From my description, I hope it’s clear that the scaffold functions aren’t especially space-efficient. Probably most people don’t care about a few hundred or few thousand bytes of code wasted, but it’s easy to see where some optimizations could be made:
When the compiler knows ahead of time that RTC checking is disabled, it should completely eliminate the functions related to RTC initialization and cleanup, instead of retaining them but having them iterate over an empty function table.
If the main() function doesn’t use argc and argv, then don’t bother to call get_command_line_args().
The compiler must know whether it’s making a native or managed app, so it can set the scaffold behavior as needed for each case. This would be far simpler than including code to parse the PE header at runtime, and shutdown/cleanup code that must handle both native and managed cases.
Bypassing the Scaffolding
While the inefficiencies of the scaffold code are annoying, what’s more bothersome is that many of the scaffold features simply can’t be turned off by any compiler setting that I’ve found. If we group the scaffold functions into broad categories, it looks like this:
- buffer overrun detection
- SEH handling
- run-time error checks (RTC)
- math error handling and default precision
- exit callbacks
- thread local storage
- command line args
- managed/native app detection
- locale settings
It would be great if there were compiler settings that could be used to disable each of these features when appropriate, for squeezing the last few hundred bytes out of the code. What’s maddening is that there are settings to disable the first two, but it appears they only prevent the features from being used in the main body of code. Support for the features is still present in the executable, because the scaffolding code uses them.
Another approach is to define a custom entry point for the program, and bypass the scaffolding completely. This could be as simple as adding
int MyEntryPoint()
{
return main(0, NULL);
}
and then setting the program’s entry point to MyEntryPoint in the advanced linker settings. This causes all of the standard scaffold code to be omitted, and with my example program it shrunk the executable from 6144 to 2560 bytes. It also drastically reduced the number of external functions in the imports list, from 38 to 3.
Caution: when using this approach, none of the standard systems will be initialized. The program will misbehave or crash if it attempts to use the command line args, or thread local storage, or locale-dependent functions in the C runtime. The custom entry point can initialize many of these manually if needed. Most of the necessary functions like __getmainargs are documented in MSDN. The rest can be handled by using the debugger to examine the scaffold code, and copying what it does.
Read 7 comments and join the conversation